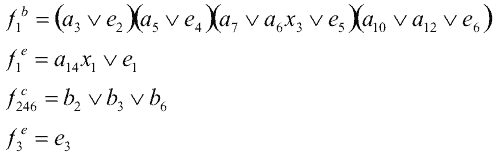Александр Владимирович НЕМЧЕНКО аспирант Харьковского национального университета
радиоэлектроники (известный как ХИРЭ) e-mail:alexandre_n@mail.ru www:alexandre-n.narod.ru
Параллельные цифровые автоматы - подготовка к синтезу
Введение
В предыдущей статье я рассказал о понятии "параллельных
цифровых автоматов" (ПЦА). Все там было так классно описано, а вот примера
не было ни одного... Этот недостаток я решил исправить в данном опусе. Будет
показан параллельный алгоритм и подготовка к синтезу (собственно синтез в универсальном
базисе "И", "ИЛИ", "НЕ"
и с использованием языка описания аппаратуры VHDL будет показан в следующей
статье - уж больно объемной выходит эта...).
Параллельный алгоритм
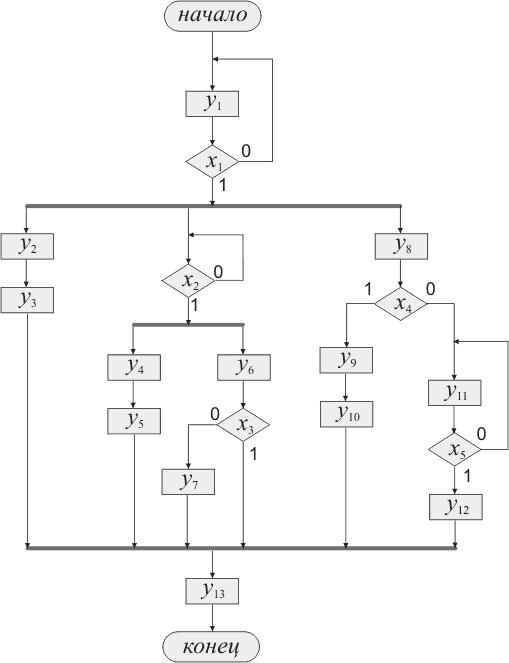
Самый понятный для нас способ описания алгоритма - это граф-схема алгоритма
(ГСА). Давайте для примера возьмем нечто абстрактное - для начала так будет
проще. Любители конкретных примеров - не волнуйтесь, в будущем рассмотрим что-нибудь
совсем реальное :-)! Ну а теперь - рис. 1.
Рис. 1 Граф-схема некоторого алгоритма
Итак, необходимо построить устройство с алгоритмом работы, показанном выше.
Устройство принимает входные сигналы x1,
x2, ..., x5.
Результатом работы являются выходные сигналы y1,
y2, ..., y13.
Вначале работы, после выполнения условия x1,
идет распараллеливание - появляются новые потоки. Все они выполняются со своими
циклами. Внутри порождаются еще два потока. Потом они все объединются в один
поток. Объединение происходит когда... Кстати, действительно, когда?
Самое простое - дождаться окончания работы всех потоков. Но можно дождаться
первого потока, а остальным дать доработать. А можно и не давать доработать...
Эти размышления показывают, что все не так просто, как хотелось бы. Есть разные
виды синхронизации работы. А есть еще и флаги, семафоры, мьютексы... Много чего
есть! Но на этом останавливаться в этой работе я не буду. Тут пока ограничимся
самой простой синхронизацией - будем дожидаться конца работы всех потоков
("все" - это те потоки, которые в конце ограничены одной линией -
"синхронизатором") .
Итак, алгоритм понятен, переходим к подготовке к синтезу.
Переход к диаграмме состояний
Первым делом нам необходимо перейти к состояниям, так как цифровой автомат
базируется именно на них.
Есть два основных метода формирования состояний и, фактически, двух разных
типов автомата,- автомат Мили и автомат Мура. Чтобы было проще (напоминаю, что
цель - показать синтез, а не закапываться в подробности), выберем автомат Мура.
Для КЦА Мура правила отметки состояний следующие: 1) отмечаем состоянием a1
первую и последнюю вершину ("начало" и "конец"),
2) отмечаем a2,
a3, ... все последующие
операторные вершины. Полученные отметки соединяются также, как и в ГСА,
но с учетом условных вершин. В результате получается диаграмма состояний.
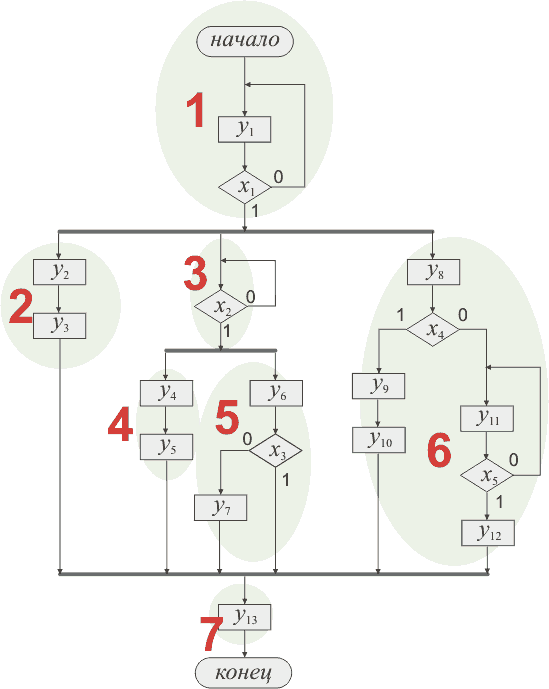
Очевидно, что в ПЦА все будет несколько иначе. В чем будет разница?
Прежде всего нам явно необходимо выделить потоки. Процесс прост (пока не будем
углубляться в дебри определений - процесс действительно прост и очевиден!).
Вот что у нас получилось:
Рис. 2 Алгоритм с выделенными потоками
Каждый поток - это самый что ни на есть обыкновенный последовательный цифровой
автомат! Следовательно, для него осхраняются все правила разметки состояний,
последующего кодирования состояний, оптимизации и так далее. Впрочем, есть один
момент. При отметке состояний КЦА последнее и начальное состояние отмечается
как одно - a1.
Так ли это в нашем случае?
Каждый поток может прибывать в двух состояниях - рабочее
и нерабочее. Если рабочее, то идет обычная смена состояний. Если нерабочее -
то это или ожидание начала работы или ожидание конца при синхронизации (2-ой
поток закончится явно раньше 4-го, 5-го и 6-го - отож ему и придется ждать конца
их работы).
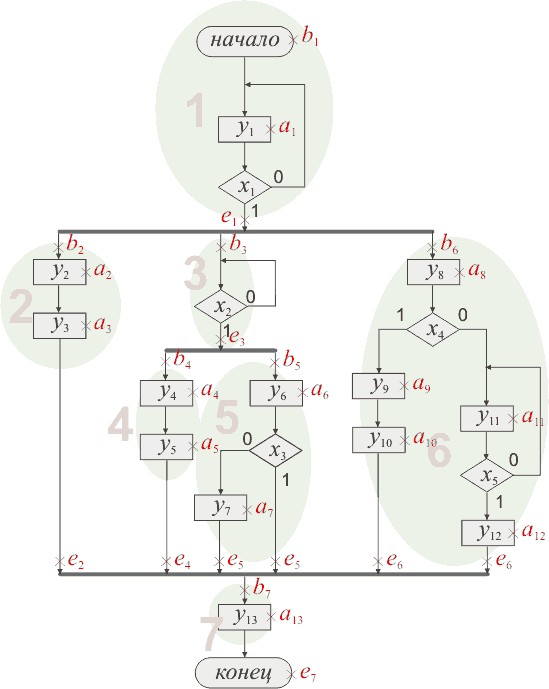
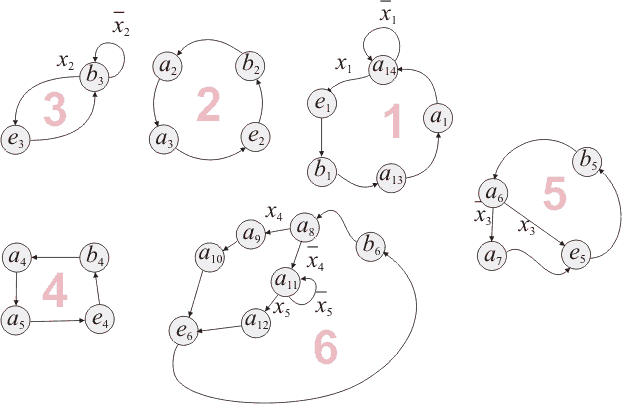
Попробуем сделать отметку по этим принципам. Попробовали? Тогда смотрите рисунок
3:
Рис. 3 Алгоритм с отмеченными состояниями
Здесь состояниями b1,
b2, ... отмечены
начала потоков, e1,
e2, ... - концы,
а a1, a2,
... - операторные вершины (обычные состояния).
В дальнейшем будет произведено кодирование состояний для каждого потока. Так
как автомат цифровой, а цифра вся двоичная :-), то для каждого
потока разрядность регистра с состоянием определяется следующей формулой:
(1)
nreg - необходимый
размер памяти регистра для записи состояний в количестве na.
Составим таблицу с расчетом необходимых размеров памяти:
Таблица 1. Размер памяти для каждого потока
Поток
Число
состояний
Объем
памяти, бит
1
3
2
2
4
2
3
2
1
4
4
2
5
4
2
6
7
3
7
3
2
Итого требуется 2+2+1+2+2+3+2=14 бит памяти.
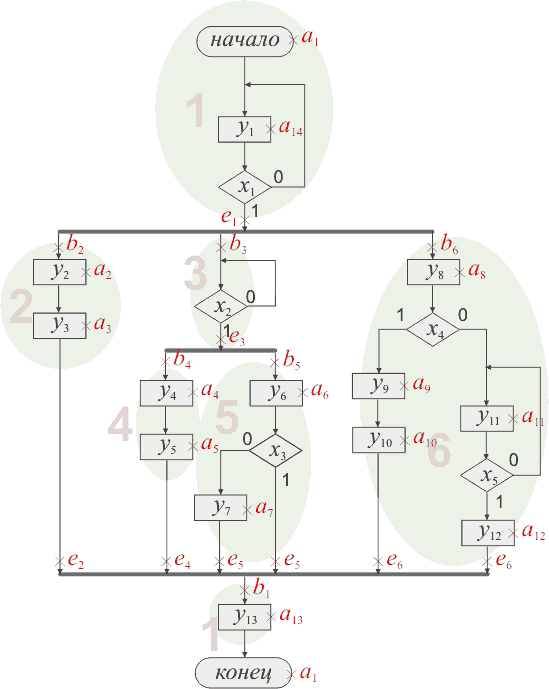
Можно объединить потоки 1-ый и 7-ой. Все получается вполне логично - у КЦА
работа начинается и заканчивается одним и тем же состоянием. Фактически КЦА
всегда зациклен. А объединение этих потоков и соединение состояний b1
и e7 вполне удовлетворяет
этому условию. Таким образом, уберем седьмой поток. Очевидно, что произойдут
изменения в состояниях:
b1 - это
состояние объединяется с e7.
Следуя традиции разметки состояний, назовем его a1;
a1 - переназовем
в a14;
e1 - остается;
b7 - переназовем
в b1;
a13 - оставим
нетронутым;
e7 - уже
упразднили :-).
Таким образом, мы получаем новую разметку состояний:
Рис. 4 Алгоритм с отмеченными состояниями (отпимизировано)
Теперь мы перейдем к диаграмме состояний. Пока что не будем описывать условия
перехода вершин b и e
- об этом будет сказано дальше. В этой диаграмме будут
присутствовать квазинезависимые :-) КЦА. Но связь между ними как
раз и будет заключаться в условиях переходов вышеназванных вершин. Диаграмма
состояний показана ниже:
Рис. 5 Недоделанная диаграмма состояний
Составление уравнений
Следующим шагом является составление уравнений.
Необходимо отметить, что этот шаг можно опускать, когда планируется синтез
устройства на устройствах программируемой логики. Но мы рассмотрим этот шаг,
чтобы было понятней.
Первым делом производится кодирование состояний. К этому делу можно подойти
просто и быстро - тогда мы получим правильный результат, но совсем неоптимальный.
Но можно здорово оптимизировать аппаратурные затраты выбором различных типов
триггеров, способов кодирования. Однако в данном примере мы поступим как раз
просто и быстро :-).
Для элементов памяти выберем D-триггер - подаваемое
на один вход число формирует состояние памяти. Составим таблицу для всех потоков:
Таблица 3. Кодирование состояний
Поток
Состояние
Код
1
a1
000
a14
001
b1
011
a13
010
e1
100
2
b2
00
a2
01
a3
11
e2
10
3
b3
0
e3
1
4
b4
00
a4
01
a5
11
e4
10
5
b5
00
a6
01
a7
11
e5
10
6
b6
000
a8
100
a9
110
a10
111
a11
101
a12
011
e6
010
Теперь, имея кодированные состояния, строим прямую таблицу переходов - перечень
всех возможных переходов. Для начала там перечислим те переходы, которые были
нами уже определены на рис. 5:
Таблица 4. Прямая таблица переходов (неполная)
Поток
Исходное
состояние
Состояние
перехода
Входной
сигнал
1
a1
a14
1
a14
a14
e1
e1
b1
1
b1
a13
1
a13
a1
1
2
b2
a2
1
a2
a3
1
a3
e2
1
e2
b2
1
3
b3
b3
e3
e3
b3
1
4
b4
a4
1
a4
a5
1
a5
e4
1
e4
b4
1
5
b5
a6
1
a6
a7
e5
a7
e5
1
e5
b5
1
6
b6
a8
1
a8
a9
a11
a9
a10
1
a10
e6
1
a11
a11
a12
a12
e6
1
e6
b6
1
Теперь пришло самое время проложить мостик между последовательными и параллельными
цифровыми автоматами - очевидно, что таблица 4 дает нам разрозненные последовательные
цифровые автоматы. Что же за переход нам нужен?
Как уже было сказано выше, поток
может пребывать в трех состояниях: 1) активные переходы из состояния в состояние,
2) ожидание старта и 3) ожидание конца. 1-ый режим эквивалентен КЦА. 2-ой имеет
место, например, в потоке 4, если x2
= 0. Ну а 3-ий - это ожидание, например, 2-ым потоком, пока потоки 4,
5, 6 не дошли до конца. А когда они все достигнут своего конца, тогда запускается
снова поток 1 (до этого он "висит" во 2-ом состоянии). Вышесказанное
можно облечь в формульный вид, если брать активное состояние как параметр.
Что нам надо доопределить, например, для 1-го потока? Автомат после состояния
a14 и соответствующего
условия оказался в состоянии e1.
И там он должен оставаться до тех пор, пока не закончатся, то есть не перейдут
в последнее состояние потоки 2, 4, 5, 6, то есть ждется выполнение следующего
условия:
(2)
И это правильно :-). Но есть тут один ньюанс. Когда все эти потоки
перейдут в свои конечные состояния, будет один пустой такт - потоки 2,
4, 5, 6 "заснули", поток 1 "не проснулся". Этого можно избежать
усложнением условия (2):
(3)
Начало работы потока 2, 3, 4, 5 определяется следующим образом:
(4)
Для упрощения структурной таблицы переходов можно обозначить формулы, возникшие
из-за параллелизма:
Формула (5.1) описывает условие перехода из состояния b1
в a13. Формула
(5.2) описывает условие старта для потоков 2, 3 и 6. (5.4) описывае тусловие
старта для потоков 4 и 6. Условие (5.3) связано с потоком 3. Он будет оставаться
в начальном условии до тех пор, пока x2
= 0. Условие же перехода из b3
в e3 связано с
концом (временным :-)) работы потока 1. Когда же все три потока
- 2, 3, 6 - выйдут из ожидания, можно переходить в состояние b1.
Поэтому вводится состояние e1
и поэтому у него условие ожидания .
Если бы не поток 3, состояние e1
вообще можно было бы не вводить.
Теперь, наконец, можно построить полную структурную таблицу переходов:
Таблица 5. Прямая структурная таблица переходов
Поток
Исходное
состояние
Код
исходного
состояния
Состояние
перехода
Код
состояния
перехода
Входной
сигнал
Функция
возбуждения
1
a1
(—)
000
a14
001
1
001
a14
(y1)
001
a14
001
001
e1
100
100
e1
(—)
100
e1
100
100
b1
011
011
b1
(—)
011
b1
011
011
a13
010
010
a13
(y13)
010
a1
000
1
000
2
b2
(—)
00
b2
00
00
a2
01
01
a2
(y2)
01
a3
11
1
11
a3
(y3)
11
b2
00
00
e2
10
10
e2
(—)
10
e2
10
10
b2
00
00
3
b3
(—)
0
b3
0
0
e3
1
1
e3
(—)
1
b3
0
1
0
4
b4
(—)
00
b4
00
00
a4
01
01
a4
(y4)
01
a5
11
1
11
a5
(y5)
11
b4
00
00
e4
10
10
e4
(—)
10
e4
10
10
b4
00
00
5
b5
(—)
00
b5
00
00
a6
01
01
a6
(y6)
01
a7
11
11
e5
10
10
b5
00
00
a7
(y7)
11
e5
10
10
b5
00
00
e5
(—)
10
e5
10
10
b5
00
00
6
b6
(—)
000
b6
000
000
a8
100
100
a8
(y8)
100
a9
110
110
a11
101
101
a9
(y9)
110
a10
111
1
111
a10
(y10)
111
b6
000
000
e6
010
010
a11
(y11)
101
a11
101
101
a12
011
011
a12
(y12)
011
e6
010
010
b6
000
000
e6
(—)
010
e6
010
010
b6
000
000
В КЦА по поступлению сигнала сброса память сбрасывается в состояние a1.
В ПЦА ситуация иная - необходимо указывать начальное состояние для каждого
потока. Какое это будет состояние? Очевидно, что для первого потока - все то
же классическое a1,
а для остальных - состояние ожидания запуска b1,
b2, ... . Для
этого формируется отдельная схема сброса.
Кратко о синтезе
Синтез в универсальном базисе похож на синтез КЦА. Для каждого потока используется
регистр памяти и дешифратор состояния. Далее для всех потоков вместе создается
матрица "И" и матрица "ИЛИ", которая
формирует новое состояние и выходные сигналы.
В отличие от КЦА вводится схема для сброса. Для этого ставится мультиплексор
перед входом регистра памяти. На адресный вход подводится условие сброса - внешний
сигнал и внутренний (если надо). На один вход подводится константный код исходного
состояния, на второй - новое состояние, определяемое данным потоком.
Синтез на языке описания аппаратуры заключается в разработке, собственно, кода,
который может быть в дальнейшем синтезирован. Шаблон для ПЦА не сильно отличается
от шаблона для КЦА.
Вначале я думал синтез показать в этой статье, но она получилась уж слишком
пузатой <:-\... Поэтому этот вопрос будет рассмотрен далее.
Выводы
В данной статье были рассмотрены подготовительные этапы к синтезу - отметка
состояний на параллельной ГСА, составление таблицы переходов, кодирование состояний,
составление структурной таблицы переходов и подготовка схемы сброса.
Дабы не перегружать эту статью, все смачные вопросы параллелизма - синхронизация,
флаги, мьютексы, семафоры, исключения и так далее - рассмотрены не были
:-). Был рассмотрен лишь простейший случай - синхронизация конца работы
всех параллельных потоков.
В следующих статьях я планирую рассмотреть собственно синтез в универсальном
базисе и на языке описания аппаратуры VHDL. Ну а далее, если Бог пошлет кучу
обворожительных муз и неглючный компьютер вместе с Интернетом, я рассмотрю различные
способы синхронизации. Ну а коли вообще произойдет чудо, то я освою Verilog
и опишу шаблон синтеза для него :-)!