Оглавление
| Введение
| П1
| П2
| П3
| Литература
Лекции:
1,
2-3,
4-6,
7.1,
7.2,
8,
9,
10,
11.1,
11.2-12,
13-14,
15-16
Лекция 9. Описание нейронных сетей
В первой части этой главы описана система построения сетей из элементов. Описаны прямое и обратное функционирование сетей и составляющих их элементов. Приведены три метода построения двойственных сетей и обоснован выбор самодвойственных сетей. Во второй части приведены примеры различных парадигм нейронных сетей, описанные в соответствии с предложенной в первой части главы методикой.
Как уже говорилось главе «Двойственные сети», на данный момент в нейросетевом сообществе принято описывать архитектуру нейронных сетей в неразрывном единстве с методами их обучения. Эта связь не является естественной. Так, в первой части этой главы будет рассматриваться только архитектура нейронных сетей. Во второй части будет продемонстрирована независимость ряда методов обучения нейронных сетей от их архитектуры. Однако, для удобства, во второй части главы архитектуры всех парадигм нейронных сетей будут описаны вместе с методами обучения.
Нейронные сети можно классифицировать по разным признакам. Для описания нейронных сетей в данной главе существенной является классификация по типу времени функционирования сетей. По этому признаку сети можно разбить на три класса.
- Сети с непрерывным временем.
- Сети с дискретным асинхронным временем.
- Сети с дискретным временем, функционирующие синхронно.
В данной работе рассматриваются только сети третьего вида, то есть сети, в которых все элементы каждого слоя срабатывают одновременно и затем передают свои сигналы нейронам следующего слоя.
Конструирование нейронных сетей
Впервые последовательное описание конструирования нейронных сетей из элементов было предложено в книге А.Н. Горбаня [65]. Однако за прошедшее время предложенный А.Н. Горбанем способ конструирования претерпел ряд изменений.
При описании нейронных сетей принято оперировать такими терминами, как нейрон и слой. Однако, при сравнении работ разных авторов выясняется, что если слоем все авторы называют приблизительно одинаковые структуры, то нейроны разных авторов совершенно различны. Таким образом, единообразное описание нейронных сетей на уровне нейронов невозможна. Однако, возможно построение единообразного описания на уровне составляющих нейроны элементов и процедур конструирования сложных сетей из простых.
Элементы нейронной сети
 |
На рис. 1 приведены все элементы, необходимые для построения нейронных сетей. Естественно, что возможно расширение списка нелинейных преобразователей. Однако, это единственный вид элементов, который может дополняться. Вертикальными стрелками обозначены входы параметров (для синапса – синаптических весов или весов связей), а горизонтальными – входные сигналы элементов. С точки зрения функционирования элементов сети сигналы и входные параметры элементов равнозначны. Различие между этими двумя видами параметров относятся к способу их использования в обучении. Кроме того, удобно считать, что параметры каждого элемента являются его свойствами и хранятся при нем. Совокупность параметров всех элементов сети называют вектором параметров сети. Совокупность параметров всех синапсов называют вектором обучаемых параметров сети, картой весов связей или синаптической картой. Отметим, что необходимо различать входные сигналы элементов и входные сигналы сети. Они совпадают только для элементов входного слоя сети.
 |
Из приведенных на рис. 1 элементов можно построить практически любую нейронную сеть. Вообще говоря, нет никаких правил, ограничивающих свободу творчества конструктора нейронных сетей. Однако, есть набор структурных единиц построения сетей, позволяющий стандартизовать процесс конструирования. Детальный анализ различных нейронных сетей позволил выделить следующие структурные единицы:
элемент – неделимая часть сети, для которой определены методы прямого и обратного функционирования;
каскад – сеть составленная из последовательно связанных слоев, каскадов, циклов или элементов;
слой – сеть составленная из параллельно работающих слоев, каскадов, циклов или элементов;
цикл – каскад выходные сигналы которого поступают на его собственный вход.
Очевидно, что не все элементы являются неделимыми. В следующем разделе будет приведен ряд составных элементов.
Введение трех типов составных сетей связано с двумя причинами: использование циклов приводит к изменению правил остановки работы сети, описанных в разд. «Правила остановки работы сети»; разделение каскадов и слоев позволяет эффективно использовать ресурсы параллельных ЭВМ. Действительно, все сети, входящие в состав слоя, могут работать независимо друг от друга. Тем самым при конструировании сети автоматически закладывается база для использования параллельных ЭВМ.
На рис. 2 приведен пример поэтапного конструирования трехслойной сигмоидной сети.
Составные элементы
Название «составные элементы» противоречит определению элементов. Это противоречие объясняется соображениями удобства работы. Введение составных элементов преследует цель упрощения конструирования. Как правило, составные элементы являются каскадами простых элементов.
 |
Хорошим примером полезности составных элементов может служить использование сумматоров. В ряде работ [36, 53, 107, 127, 289] интенсивно используются сети, нейроны которых содержат нелинейные входные сумматоры. Под нелинейным входным сумматором, чаще всего понимают квадратичные сумматоры – сумматоры, вычисляющие взвешенную сумму всех попарных произведений входных сигналов нейрона. Отличие сетей с квадратичными сумматорами заключается только в использовании этих сумматоров. На рис. 3а приведен фрагмент сети с линейными сумматорами. На рис. 3б – соответствующий ему фрагмент с квадратичными сумматорами, построенный с использованием элементов, приведенных на рис. 1. На (рис. 3в) – тот же фрагмент, построенный с использованием квадратичных сумматоров. При составлении сети с квадратичными сумматорами из простых элементов на пользователя ложится большой объем работ по проведению связей и организации вычисления попарных произведений. Кроме того, рис. 3в гораздо понятнее рис. 3б и содержит ту же информацию. Кроме того, пользователь может изменить тип сумматоров уже сконструированной сети, указав замену одного типа сумматора на другой. На рис. 4 приведены обозначения и схемы наиболее часто используемых составных элементов.
Необходимо отметить еще одну разновидность сумматоров, полезную при работе по конструированию сети – неоднородные сумматоры. Неоднородный сумматор отличается от однородного наличием еще одного входного сигнала, равного единице. На рис. 4г приведены схема и обозначения для неоднородного адаптивного сумматора. В табл. 1 приведены значения, вычисляемые однородными и соответствующими им неоднородными сумматорами.
Таблица 1
Однородные и неоднородные сумматоры
| Название |
Однородный сумматор |
Неоднородный сумматор |
| Обозначение |
Значение |
Обозначение |
Значение |
| Обычный |
S |
 |
S+ |
 |
| Адаптивный |
A |
 |
A+ |
 |
| Квадратичный |
Q |
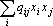 |
Q+ |
 |
Функционирование сети

Рис. 5 Схема функционирования сети |
Прежде всего, необходимо разделить процессы обучения нейронной сети и использования обученной сети. При использовании обученной сети происходит только решение сетью определенной задачи. При этом синаптическая карта сети остается неизменной. Работу сети при решении задачи будем далее называть прямым функционированием.
При обучении нейронных сетей методом обратного распространения ошибки нейронная сеть (и каждый составляющий ее элемент) должна уметь выполнять обратное функционирование. Во второй части этой главы будет показано, что обратное функционирование позволяет обучать также и нейросети, традиционно считающиеся не обучаемыми, а формируемыми (например, сети Хопфилда [312]). Обратным функционированием называется процесс работы сети, когда на вход двойственной сети подаются определенные сигналы, которые далее распространяются по связям двойственной сети. При прохождении сигналов обратного функционирования через элемент, двойственный элементу с обучаемыми параметрами, вычисляются поправки к параметрам этого элемента. Если на вход сети, двойственной к сети с непрерывными элементами, подается производная некоторой функции F от выходных сигналов сети, то вычисляемые сетью поправки должны быть элементами градиента функции F по обучаемым параметрам сети. Двойственная сеть строится так, чтобы удовлетворять этому требованию.
Методы построения двойственных сетей
Пусть задана нейронная сеть, вычисляющая некоторую функцию (рис. 5а). Необходимо построить двойственную к ней сеть, вычисляющую градиент некоторой функции H от выходных сигналов сети. В книге А.Н. Горбаня «Обучение нейронных сетей» [65] предложен метод построения сети, двойственной к данной. Пример сети, построенной по методу А.Н. Горбаня, приведен на рис. 5б. Для работы такой сети необходимо, обеспечение работы элементов в трех режимах. Первый режим – обычное прямое функционирование (рис. 5а). Второй режим – нагруженное прямое функционирование (рис. 5б, верхняя цепочка). Третий режим – обратное функционирование.
При обычном прямом функционировании каждый элемент вычисляет выходную функцию от входных сигналов и параметров и выдает ее на выход в сеть для передачи далее.
При нагруженном прямом функционировании каждый элемент вычисляет выходную функцию от входных сигналов и параметров и выдает ее на выход в сеть для передачи далее. Кроме того, он вычисляет производные выходной функции по каждому входному сигналу и параметру и запоминает их (блоки под элементами в верхней цепочке на рис. 5б). При обратном функциони-ровании элементы исход-ной сети выдают на специальные выходы ранее вычисленные производные (связи между верхней и нижней цепочками на рис. 5б), которые далее используются для вычисления градиентов по параметрам и входным сигналам сети двойственной сетью (нижняя цепочка на рис. 5б). Вообще говоря, для хорошей организации работы такой сети требуется одно из следующих устройств. Либо каждый элемент должен получать дополнительный сигнал выдачи запомненных сигналов (ранее вычисленных производных), либо к сети следует добавить элемент, вычисляющий функцию оценки.
Первое решение требует дополнительных линий связи с каждым элементом, за исключением точек ветвления, что в существенно увеличивает (приблизительно в полтора раза) и без того большое число связей. Большое число связей, в свою очередь, увеличивает сложность и стоимость аппаратной реализации нейронной сети.
Второй подход – включение оценки как элемента в нейронную сеть – лишает структуру гибкости, поскольку для замены функции оценки потребуется изменять сеть. Кроме того, оценка будет достаточно сложным элементом. некоторые оценки включают в себя процедуру сортировки и другие сложные операции (см. главу «Оценка и интерпретатор ответа»).
Метод нагруженного функционирования позволяет вычислять не только градиент оценки, но и производные по входным параметрам и сигналам от произвольного функционала от градиента. Для этого строится дважды двойственная сеть. Для работы дважды двойственной сети необходимо, чтобы элементы выполняли дважды двойственное функционирование – вычисляли не только выходной сигнал и производные выходного сигнала по входным сигналам и параметрам, но и матрицу вторых производных выходного сигнала по входным сигналам и параметрам. Кроме того, построение дважды двойственной сети потребует дополнительных затрат от пользователя, поскольку процедура построения двойственной и дважды двойственной сети достаточно понятна, но описывается сложным алгоритмом. При этом построение дважды двойственной сети не является построением сети двойственной к двойственной.
Для унификации процедуры построения сети, двойственной к данной сети, автором разработан унифицированный метод двойственности. В этом методе каждому элементу исходной сети ставится в соответствие подсеть. На рис. 5в приведен пример двойственной сети, построенной по унифицированному методу. Каждый элемент, кроме точки ветвления и сумматора, заменяется на элемент, вычисляющий производную выходной функции исходного элемента по входному сигналу (параметру) и умножитель, умножающий сигнал обратного функционирования на вычисленную производную. Если элемент имеет несколько входов и параметров, то он заменяется на столько описанных выше подсетей, сколько у него входных сигналов и параметров. При этом сигнал обратного функционирования пропускается через точку ветвления.
Двойственная сеть, построенная по этому методу, требует включения в нее оценки как элемента. Достоинством этого метода является универсальность. Для построения дважды двойственной сети достаточно построить сеть двойственную к двойственной. Кроме того, построенная по этому методу сеть имеет меньшее время срабатывания.
Анализ этих двух методов с точки зрения аппаратной реализации, выявил в них следующие недостатки.
- Для реализации обратного функционирования необходимо изменять архитектуру сети, причем в ходе обратного функционирования связи прямого функционирования не используются.
- Необходимо включать в сеть оценку как один из элементов
Для устранения этих недостатков, автором предложен метод самодвойственных сетей. Этот метод не позволяет строить дважды двойственных сетей, что делает его менее мощным, чем два предыдущих. Однако большинство методов обучения не требует использования дважды двойственных сетей, что делает это ограничение не очень существенным. Идея самодвойственных сетей состоит в том, чтобы каждый элемент при прямом функционировании запоминал входные сигналы. А при обратном функционировании вычислял все необходимые производные, используя ранее запомненные сигналы, и умножал их на сигнал обратного функционирования.
Такая модификация делает элементы более сложными, чем в двух предыдущих методах. Однако этот метод дает следующие преимущества по отношению к методу нагруженного функционирования и унифицированному методу двойственности.
- Для элементов не требуется дополнительного управления, поскольку получение сигнала прямого или обратного функционирования инициирует выполнение одной из двух функций.
- Для выполнения обратного функционирования не требуется дополнительных элементов и линий связи между элементами.
- Оценка является независимым от сети компонентом.
Наиболее существенным является второе преимущество, поскольку при аппаратной реализации нейронных сетей наиболее существенным ограничением является число связей. Так в приведенных на рис. 5 сетях задействовано для самодвойственной сети – 6 связей, для сети, построенной по методу нагруженного функционирования – 20 связей, а для сети, построенной по методу унифицированной двойственности – 27 связей. Следует заметить, что с ростом размеров сети данные пропорции будут примерно сохраняться.
Исходя из соображений экономичной и эффективной аппаратной реализации и функционального разделения компонентов далее в данной работе рассматриваются только самодвойственные сети.
Элементы самодвойственных сетей
Если при обратном функционировании самодвойственной сети на ее выход подать производные некоторой функции F по выходным сигналам сети, то в ходе обратного функционирования на входах параметров сети должны быть вычислены элементы градиента функции F по параметрам сети, а на входах сигналов – элементы градиента функции F по входным сигналам. Редуцируя это правило на отдельный элемент, получаем следующее требование к обратному функционированию элемента самодвойственной сети: Если при обратном функционировании элемента самодвойственной сети на его выход подать производные некоторой функции F по выходным сигналам элемента, то в ходе обратного функционирования на входах параметров элемента должны быть вычислены элементы градиента функции F по параметрам элемента, а на входах сигналов – элементы градиента функции F по входным сигналам элемента. Легко заметить, что данное требование автоматически обеспечивает подачу на выход элемента, предшествующего данному, производной функции F по выходным сигналам этого элемента.
Далее в этом разделе для каждого из элементов, приведенных на рис.1 определены правила обратного функционирования, в соответствии со сформулированными выше требованиями к элементам самодвойственной сети.
Синапс
У синапса два входа – вход сигнала и вход синаптического веса (рис. 6а). Обозначим входной сигнал синапса через x, а синаптический вес через α. Тогда выходной сигнал синапса равен αx. При обратном функционировании на выход синапса подается сигнал  . На входе синапса должен быть получен сигнал обратного функционирования, равный . На входе синапса должен быть получен сигнал обратного функционирования, равный  , а на входе синаптического веса – поправка к синаптическому весу, равная , а на входе синаптического веса – поправка к синаптическому весу, равная  (рис. 6б). (рис. 6б).
Умножитель
Умножитель имеет два входных сигнала и не имеет параметров. Обозначим входные сигнал синапса через  . Тогда выходной сигнал умножителя равен . Тогда выходной сигнал умножителя равен  (рис. 7а). При обратном функционировании на выход умножителя подается сигнал (рис. 7а). При обратном функционировании на выход умножителя подается сигнал  . На входах сигналов . На входах сигналов  и и  должны быть получены сигналы обратного функционирования, равные должны быть получены сигналы обратного функционирования, равные  и и  , соответственно (рис. 7б). , соответственно (рис. 7б).
Точка ветвления
В отличие от ранее рассмотренных элементов, точка ветвления имеет только один вход и несколько выходов. Обозначим входной сигнал через x, а выходные через  , причем , причем  (рис. 8а). При обратном функционировании на выходные связи точки ветвления подаются сигналы (рис. 8а). При обратном функционировании на выходные связи точки ветвления подаются сигналы  (рис. 8б). На входной связи должен получаться сигнал, равный (рис. 8б). На входной связи должен получаться сигнал, равный  . Можно сказать, что точка ветвления при обратном функционировании переходит в сумматор, или, другими словами, сумматор является двойственным по отношению к точке ветвления. . Можно сказать, что точка ветвления при обратном функционировании переходит в сумматор, или, другими словами, сумматор является двойственным по отношению к точке ветвления.
Сумматор
Сумматор считает сумму входных сигналов. Обычный сумматор не имеет параметров. При описании прямого и обратного функционирования ограничимся описанием простого сумматора, поскольку функционирование адаптивного и квадратичного сумматора может быть получено как прямое и обратное функционирование сети в соответствии с их схемами, приведенными на рис. 3б и 3в. Обозначим входные сигналы сумматора через (рис. 9а). Выходной сигнал равен  . При обратном функционировании на выходную связь сумматора подается сигнал . При обратном функционировании на выходную связь сумматора подается сигнал  (рис. 9б). На входных связях должны получаться сигналы, равные (рис. 9б). На входных связях должны получаться сигналы, равные  . Из последней формулы следует, что все сигналы обратного функционирования, выдаваемые на входные связи сумматора, равны. Таким образом сумматор при обратном функционировании переходит в точку ветвления, или, другими словами, сумматор является двойственным по отношению к точке ветвления. . Из последней формулы следует, что все сигналы обратного функционирования, выдаваемые на входные связи сумматора, равны. Таким образом сумматор при обратном функционировании переходит в точку ветвления, или, другими словами, сумматор является двойственным по отношению к точке ветвления.
Нелинейный Паде преобразователь
Нелинейный Паде преобразователь или Паде элемент имеет два входных сигнала и один выходной. Обозначим входные сигналы через . Тогда выходной сигнал Паде элемента равен  (рис. 10а). При обратном функционировании на выход Паде элемента подается сигнал (рис. 10а). При обратном функционировании на выход Паде элемента подается сигнал  . На входах сигналов и должны быть получены сигналы обратного функционирования, равные . На входах сигналов и должны быть получены сигналы обратного функционирования, равные  и и  , соответственно (рис. 10б). , соответственно (рис. 10б).
Нелинейный сигмоидный преобразователь
Нелинейный сигмоидный преобразователь или сигмоидный элемент имеет один входной сигнал и один параметр. Сторонники чистого коннекционистского подхода считают, что обучаться в ходе обучения нейронной сети могут только веса связей. С этой точки зрения параметр сигмоидного элемента является не обучаемым и, как следствие, для него нет необходимости вычислять поправку. Однако, часть исследователей полагает, что нужно обучать все параметры всех элементов сети. Исходя из этого, опишем вычисление этим элементом поправки к содержащемуся в нем параметру.
Обозначим входной сигнал через x, параметр через α, а вычисляемую этим преобразователем функцию через  (рис. 11а). При обратном функционировании на выход сигмоидного элемента подается сигнал (рис. 11а). При обратном функционировании на выход сигмоидного элемента подается сигнал  . На входе сигнала должен быть получен сигнал обратного функционирования, равный . На входе сигнала должен быть получен сигнал обратного функционирования, равный  , а на входе параметра поправка, равная , а на входе параметра поправка, равная  (рис. 11б). (рис. 11б).
Произвольный непрерывный нелинейный преобразователь
Произвольный непрерывный нелинейный преобразователь имеет несколько входных сигналов, а реализуемая им функция зависит от нескольких параметров. Выходной сигнал такого элемента вычисляется как некоторая функция  , где x – вектор входных сигналов, а a – вектор параметров. При обратном функционировании на выходную связь элемента подается сигнал обратного функционирования, равный , где x – вектор входных сигналов, а a – вектор параметров. При обратном функционировании на выходную связь элемента подается сигнал обратного функционирования, равный  . На входы сигналов выдаются сигналы обратного функционирования, равные . На входы сигналов выдаются сигналы обратного функционирования, равные  , а на входах параметров вычисляются поправки, равные , а на входах параметров вычисляются поправки, равные
Пороговый преобразователь
 |
Пороговый преобразователь, реализующий функцию определения знака (рис. 12а), не является элементом с непрерывной функцией, и, следовательно, его обратное функционирование не может быть определено из требования вычисления градиента. Однако, при обучении сетей с пороговыми преобразователями полезно иметь возможность вычислять поправки к параметрам. Так как для порогового элемента нельзя определить однозначное поведение при обратном функционировании, предлагается доопределить его, исходя из соображений полезности при конструировании обучаемых сетей. Основным методом обучения сетей с пороговыми элементами является правило Хебба (подробно рассмотрено во второй части главы). Оно состоит из двух процедур, состоящих в изменении «весов связей между одновременно активными нейронами». Для этого правила пороговый элемент при обратном функционировании должен выдавать сигнал обратного функционирования, совпадающий с выданным им сигналом прямого функционирования (рис. 12б). Такой пороговый элемент будем называть зеркальным. При обучении сетей Хопфилда [312], подробно рассмотренном во второй части главы, необходимо использовать «прозрачные» пороговые элементы, которые при обратном функционировании пропускают сигнал без изменения (рис. 12в).
Правила остановки работы сети
При использовании сетей прямого распространения (сетей без циклов) вопроса об остановке сети не возникает. Действительно, сигналы поступают на элементы первого (входного) слоя и, проходя по связям, доходят до элементов последнего слоя. После снятия сигналов с последнего слоя все элементы сети оказываются «обесточенными», то есть ни по одной связи сети не проходит ни одного ненулевого сигнала. Сложнее обстоит дело при использовании сетей с циклами. В случае общего положения, после подачи сигналов на входные элементы сети по связям между элементами, входящими в цикл, ненулевые сигналы будут циркулировать сколь угодно долго.
Существует два основных правила остановки работы сети с циклами. Первое правило состоит в остановке работы сети после указанного числа срабатываний каждого элемента. Циклы с таким правилом остановки будем называть ограниченными.
Второе правило остановки работы сети – сеть прекращает работу после установления равновесного распределения сигналов в цикле. Такие сети будем называть равновесными. Примером равновесной сети может служить сеть Хопфилда [312] (см. разд. «Сети Хопфилда»).
Архитектуры сетей
Как уже отмечалось ранее, при конструировании сетей из элементов можно построить сеть любой архитектуры. Однако и при произвольном конструировании можно выделить наиболее общие признаки, существенно отличающие одну сеть от другой. Очевидно, что замена простого сумматора на адаптивный или даже на квадратичный не приведут к существенному изменению структуры сети, хотя число обучаемых параметров увеличится. Однако, введение в сеть цикла сильно изменяет как структуру сети, так и ее поведение. Таким образом можно все сети разбить на два сильно отличающихся класса: ациклические сети и сети с циклами. Среди сетей с циклами существует еще одно разделение, сильно влияющее на способ функционирования сети: равновесные сети с циклами и сети с ограниченными циклами.
Большинство используемых сетей не позволяют определить, как повлияет изменение какого-либо внутреннего параметра сети на выходной сигнал. На рис. 13 приведен пример сети, в которой увеличение параметра α приводит к неоднозначному влиянию на сигнал : при отрицательных произойдет уменьшение , а при положительных – увеличение. Таким образом, выходной сигнал такой сети немонотонно зависит от параметра α. Для получения монотонной зависимости выходных сигналов сети от параметров внутренних слоев (то есть всех слоев кроме входного) необходимо использовать специальную монотонную архитектуру нейронной сети. Принципиальная схема сетей монотонной архитектуры приведена на рис. 14.
 |
Основная идея построения монотонных сетей состоит в разделении каждого слоя сети на два – возбуждающий и тормозящий. При этом все связи в сети устроены так, что элементы возбуждающей части слоя возбуждают элементы возбуждающей части следующего слоя и тормозят тормозящие элементы следующего слоя. Аналогично, тормозящие элементы возбуждают тормозящие элементы и тормозят возбуждающие элементы следующего слоя. Названия «тормозящий» и «возбуждающий» относятся к влиянию элементов обеих частей на выходные элементы.
Отметим, что для сетей с сигмоидными элементами требование монотонности означает, что веса всех связей должны быть неотрицательны. Для сетей с Паде элементами требование не отрицательности весов связей является необходимым условием бессбойной работы. Требование монотонности для сетей с Паде элементами приводит к изменению архитектуры сети, не накладывая никаких новых ограничений на параметры сети. На рис. 15 приведены пример немонотонной сети, а на рис. 16 монотонной сети с Паде элементами.
Особо отметим архитектуру еще одного класса сетей – сетей без весов связей. Эти сети, в противовес коннекционистским, не имеют обучаемых параметров связей. Любую сеть можно превратить в сеть без весов связей заменой всех синапсов на умножители. Легко заметить, что получится такая же сеть, только вместо весов связей будут использоваться сигналы. Таким образом в сетях без весов связей выходные сигналы одного слоя могут служить для следующего слоя как входными сигналами, так и весами связей. Заметим, что вся память таких сетей содержится в значениях параметров нелинейных преобразователей. Из разделов «Синапс» и «Умножитель» следует, что сети без весов связей способны вычислять градиент функции оценки и затрачивают на это ровно тоже время, что и аналогичная сеть с весами связей.
Модификация синаптической карты (обучение)
Кроме прямого и обратного функционирования, все элементы должны уметь выполнять еще одну операцию – модификацию параметров. Процедура модификации параметров состоит в добавлении к существующим параметрам вычисленных поправок (напомним, что для сетей с непрерывно дифференцируемыми элементами вектор поправок является градиентом некоторой функции от выходных сигналов). Если обозначить текущий параметр элемента через α, а вычисленную поправку через  , то новое значение параметра вычисляется по формуле , то новое значение параметра вычисляется по формуле  . Параметры обучения . Параметры обучения  и и  определяются компонентом учитель и передаются сети вместе с запросом на обучение. В некоторых случаях бывает полезно использовать более сложную процедуру модификации карты. определяются компонентом учитель и передаются сети вместе с запросом на обучение. В некоторых случаях бывает полезно использовать более сложную процедуру модификации карты.
Во многих работах отмечается, что при описанной выше процедуре модификации параметров происходит неограниченный рост величин параметров. Существует несколько различных методов решения этой проблемы. Наиболее простым является жесткое ограничение величин параметров некоторыми минимальным и максимальным значениями. При использовании этого метода процедура модификации параметров имеет следующий вид:

Контрастирование и нормализация сети
В последние годы широкое распространение получили различные методы контрастирования или скелетонизации нейронных сетей. В ходе процедуры контрастирования достигается высокая степень разреженности синаптической карты нейронной сети, так как большинство связей получают нулевые веса (см. например [47, 100, 303. 304]).
Очевидно, что при такой степени разреженности ненулевых параметров проводить вычисления так, как будто структура сети не изменилась, неэффективно. Возникает потребность в процедуре нормализации сети, то есть фактического удаления нулевых связей из сети, а не только из обучения. Процедура нормализации состоит из двух этапов:
- Из сети удаляются все связи, имеющие нулевые веса и исключенные из обучения.
- Из сети удаляются все подсети, выходные сигналы которых не используются другими подсетями в качестве входных сигналов и не являются выходными сигналами сети в целом.
В ходе нормализации возникает одна трудность: если при описании нейронной сети все нейроны одинаковы, и можно описать нейрон один раз, то после удаления отконтрастированных связей нейроны обычно имеют различную структуру. Компонент сеть должен отслеживать ситуации, когда два блока исходно одного и того же типа уже не могут быть представлены в виде этого блока с различными параметрами. В этих случаях компонент сеть порождает новый тип блока. Правила порождения имен блоков приведены в описании выполнения запроса на нормализацию сети.
Примеры сетей и алгоритмов их обучения
В этом разделе намеренно допущено отступление от общей методики – не смешивать разные компоненты. Это сделано для облегчения демонстрации построения нейронных сетей обратного распространения, позволяющих реализовать на них большинство известных алгоритмов обучения нейронных сетей.
Сети Хопфилда
Классическая сеть Хопфилда [312], функционирующая в дискретном времени, строится следующим образом. Пусть  – набор эталонных образов – набор эталонных образов  . Каждый образ, включая и эталоны, имеет вид n-мерного вектора с координатами, равными нулю или единице. При предъявлении на вход сети образа x сеть вычисляет образ, наиболее похожий на x. В качестве меры близости образов выберем скалярное произведение соответствующих векторов. Вычисления проводятся по следующей формуле: . Каждый образ, включая и эталоны, имеет вид n-мерного вектора с координатами, равными нулю или единице. При предъявлении на вход сети образа x сеть вычисляет образ, наиболее похожий на x. В качестве меры близости образов выберем скалярное произведение соответствующих векторов. Вычисления проводятся по следующей формуле:  . Эта процедура выполняется до тех пор, пока после очередной итерации не окажется, что . Эта процедура выполняется до тех пор, пока после очередной итерации не окажется, что  . Вектор x, полученный в ходе последней итерации, считается ответом. Для нейросетевой реализации формула работы сети переписывается в следующем виде: . Вектор x, полученный в ходе последней итерации, считается ответом. Для нейросетевой реализации формула работы сети переписывается в следующем виде:

или

где  . .
На рис. 17 приведена схема сети Хопфилда [312] для распознавания четырехмерных образов. Обычно сети Хопфилда [312] относят к сетям с формируемой синаптической картой. Однако, используя разработанный в первой части главы набор элементов, можно построить обучаемую сеть. Для построения такой сети используем «прозрачные» пороговые элементы. Ниже приведен алгоритм обучения сети Хопфилда [312].
- Положим все синаптические веса равными нулю.
- Предъявим сети первый эталон
 и проведем один такт функционирования вперед, то есть цикл будет работать не до равновесия, а один раз (см. рис. 17б). и проведем один такт функционирования вперед, то есть цикл будет работать не до равновесия, а один раз (см. рис. 17б).
- Подадим на выход каждого нейрона соответствующую координату вектора (см. рис. 17в). Поправка, вычисленная на j-ом синапсе i-го нейрона, равна произведению сигнала прямого функционирования на сигнал обратного функционирования. Поскольку при обратном функционировании пороговый элемент прозрачен, а сумматор переходит в точку ветвления, то поправка равна
 . .
- Далее проведем шаг обучения с параметрами обучения, равными единице. В результате получим
 . .
Повторяя этот алгоритм, начиная со второго шага, для всех эталонов получим  , что полностью совпадает с формулой формирования синаптической карты сети Хопфилда [312], приведенной в начале раздела. , что полностью совпадает с формулой формирования синаптической карты сети Хопфилда [312], приведенной в начале раздела.
Сеть Кохонена
Сети Кохонена [131, 132] (частный случай метода динамических ядер [224, 262]) являются типичным представителем сетей решающих задачу классификации без учителя. Рассмотрим пространственный вариант сети Кохонена. Дан набор из m точек  в n-мерном пространстве. Необходимо разбить множество точек на k классов близких в смысле квадрата евклидова расстояния. Для этого необходимо найти k точек в n-мерном пространстве. Необходимо разбить множество точек на k классов близких в смысле квадрата евклидова расстояния. Для этого необходимо найти k точек  таких, что таких, что  , минимально; , минимально;  . .
Существует множество различных алгоритмов решения этой задачи. Рассмотрим наиболее эффективный из них.
- Зададимся некоторым набором начальных точек .
- Разобьем множество точек на k классов по правилу
 . .
- По полученному разбиению вычислим новые точки из условия минимальности
 . .
Обозначив через  число точек в i-ом классе, решение задачи, поставленной на третьем шаге алгоритма, можно записать в виде число точек в i-ом классе, решение задачи, поставленной на третьем шаге алгоритма, можно записать в виде  . .
Второй и третий шаги алгоритма будем повторять до тех пор, пока набор точек не перестанет изменяться. После окончания обучения получаем нейронную сеть, способную для произвольной точки x вычислить квадраты евклидовых расстояний от этой точки до всех точек и, тем самым, отнести ее к одному из k классов. Ответом является номер нейрона, выдавшего минимальный сигнал.
Теперь рассмотрим сетевую реализацию. Во первых, вычисление квадрата евклидова расстояния достаточно сложно реализовать в виде сети (рис. 18а). Однако заметим, что нет необходимости вычислять квадрат расстояния полностью. Действительно,
 . .
Отметим, что в последней формуле первое слагаемое не зависит от точки x, второе вычисляется адаптивным сумматором, а третье одинаково для всех сравниваемых величин. Таким образом, легко получить нейронную сеть, которая вычислит для каждого класса только первые два слагаемых (рис. 18б).
Второе соображение, позволяющее упростить обучение сети, состоит в отказе от разделения второго и третьего шагов алгоритма.
Алгоритм классификации.
- На вход нейронной сети, состоящей из одного слоя нейронов, приведенных на рис. 18б, подается вектор x.
- Номер нейрона, выдавшего минимальный ответ, является номером класса, к которому принадлежит вектор x.
Алгоритм обучения.
- Полагаем поправки всех синапсов равными нулю.
- Для каждой точки множества выполняем следующую процедуру.
- Предъявляем точку сети для классификации.
- Пусть при классификации получен ответ – класс l. Тогда для обратного функционирования сети подается вектор Δ, координаты которого определяются по следующему правилу:
 . .
- Вычисленные для данной точки поправки добавляются к ранее вычисленным.
- Для каждого нейрона производим следующую процедуру.
- Если поправка, вычисленная последним синапсом равна 0, то нейрон удаляется из сети.
- Полагаем параметр обучения равным величине, обратной к поправке, вычисленной последним синапсом.
- Вычисляем сумму квадратов накопленных в первых n синапсах поправок и, разделив на -2, заносим в поправку последнего синапса.
- Проводим шаг обучения с параметрами
 , ,  . .
- Если вновь вычисленные синаптические веса отличаются от полученных на предыдущем шаге, то переходим к первому шагу алгоритма.
В пояснении нуждается только второй и третий шаги алгоритма. Из рис. 18в видно, что вычисленные на шаге 2.2 алгоритма поправки будут равны нулю для всех нейронов, кроме нейрона, выдавшего минимальный сигнал. У нейрона, выдавшего минимальный сигнал, первые n поправок будут равны координатам распознававшейся точки x, а поправка последнего синапса равна единице. После завершения второго шага алгоритма поправка последнего синапса i-го нейрона будет равна числу точек, отнесенных к i-му классу, а поправки остальных синапсов этого нейрона равны сумме соответствующих координат всех точек i-о класса. Для получения правильных весов остается только разделить все поправки первых n синапсов на поправку последнего синапса, положить последний синапс равным сумме квадратов полученных величин, а остальные синапсы – полученным для них поправкам, умноженным на -2. Именно это и происходит при выполнении третьего шага алгоритма.
Персептрон Розенблатта
Персептрон Розенблатта [146, 181] является исторически первой обучаемой нейронной сетью. Существует несколько версий персептрона. Рассмотрим классический персептрон – сеть с пороговыми нейронами и входными сигналами, равными нулю или единице. Опираясь на результаты, изложенные в работе [146] можно ввести следующие ограничения на структуру сети.
- Все синаптические веса могут быть целыми числами.
- Многослойный персептрон по своим возможностям эквивалентен двухслойному. Все нейроны имеют синапс, на который подается постоянный единичный сигнал. Вес этого синапса далее будем называть порогом. Каждый нейрон первого слоя имеет единичные синаптические веса на всех связях, ведущих от входных сигналов, и его порог равен числу входных сигналов сумматора, уменьшенному на два и взятому со знаком минус.
Таким образом, можно ограничиться рассмотрением только двухслойных персептронов с не обучаемым первым слоем. Заметим, что для построения полного первого слоя пришлось бы использовать  нейронов, где n – число входных сигналов персептрона. На рис. 19а приведена схема полного персептрона для трехмерного вектора входных сигналов. Поскольку построение такой сети при достаточно большом n невозможно, то обычно используют некоторое подмножество нейронов первого слоя. К сожалению, только полностью решив задачу можно точно указать необходимое подмножество. Обычно используемое подмножество выбирается исследователем из каких-то содержательных соображений или случайно. нейронов, где n – число входных сигналов персептрона. На рис. 19а приведена схема полного персептрона для трехмерного вектора входных сигналов. Поскольку построение такой сети при достаточно большом n невозможно, то обычно используют некоторое подмножество нейронов первого слоя. К сожалению, только полностью решив задачу можно точно указать необходимое подмножество. Обычно используемое подмножество выбирается исследователем из каких-то содержательных соображений или случайно.
 |
Классический алгоритм обучения персептрона является частным случаем правила Хебба. Поскольку веса связей первого слоя персептрона являются не обучаемыми, веса нейрона второго слоя в дальнейшем будем называть просто весами. Будем считать, что при предъявлении примера первого класса персептрон должен выдать на выходе нулевой сигнал, а при предъявлении примера второго класса – единичный. Ниже приведено описание алгоритма обучения персептрона.
- Полагаем все веса равными нулю.
- Проводим цикл предъявления примеров. Для каждого примера выполняется следующая процедура.
- Если сеть выдала правильный ответ, то переходим к шагу 2.4.
- Если на выходе персептрона ожидалась единица, а был получен ноль, то веса связей, по которым прошел единичный сигнал, уменьшаем на единицу.
- Если на выходе персептрона ожидался ноль, а была получена единица, то веса связей, по которым прошел единичный сигнал, увеличиваем на единицу.
- Переходим к следующему примеру. Если достигнут конец обучающего множества, то переходим к шагу 3, иначе возвращаемся на шаг 2.1.
- Если в ходе выполнения второго шага алгоритма хоть один раз выполнялся шаг 2.2 или 2.3 и не произошло зацикливания, то переходим к шагу 2. В противном случае обучение завершено.
В этом алгоритме не предусмотрен механизм отслеживания зацикливания обучения. Этот механизм можно реализовывать по разному. Наиболее экономный в смысле использования дополнительной памяти имеет следующий вид.
- k=1; m=0. Запоминаем веса связей.
- После цикла предъявлений образов сравниваем веса связей с запомненными. Если текущие веса совпали с запомненными, то произошло зацикливание. В противном случае переходим к шагу 3.
- m=m+1. Если m<k, то переходим ко второму шагу.
- k=2k; m=0. Запоминаем веса связей и переходим к шагу 2.
Поскольку длина цикла конечна, то при достаточно большом k зацикливание будет обнаружено.
Для использования в обучении сети обратного функционирования, необходимо переписать второй шаг алгоритма обучения в следующем виде.
2. Проводим цикл предъявления примеров. Для каждого примера выполняется следующая процедура.
2.1. Если сеть выдала правильный ответ, то переходим к шагу 2.5.
2.2. Если на выходе персептрона ожидалась единица, а был получен ноль, то на выход сети при обратном функционировании подаем  . .
2.3. Если на выходе персептрона ожидался ноль, а была получена единица, то на выход сети при обратном функционировании подаем  . .
2.4. Проводим шаг обучения с единичными параметрами.
2.5. Переходим к следующему примеру. Если достигнут конец обучающего множества, то переходим к шагу 3, иначе возвращаемся на шаг 2.1.
На рис. 19в приведена схема обратного функционирования нейрона второго слоя персептрона. Учитывая, что величины входных сигналов этого нейрона равны нулю или единице, получаем эквивалентность модифицированного алгоритма исходному. Отметим также, что при обучении персептрона впервые встретились не обучаемые параметры – веса связей первого слоя.
Оглавление
| Введение
| П1
| П2
| П3
| Литература
Лекции:
1,
2-3,
4-6,
7.1,
7.2,
8,
9,
10,
11.1,
11.2-12,
13-14,
15-16
|











