На примере сортировки рассматриваются вопросы наложения ограничений на алгоритмы, обладающие максимальным параллелизмом, что позволяет переходить к построению программ, эффективно выполняемых на реальных вычислительных системах.
© 2004 А. И. Легалов
Введение
При разработке параллельных программ используются различные подходы. К наиболее эффективному из них в настоящее время относится написание кода, ориентированного на конкретную вычислительную систему. Однако в этом случае существует риск повторного переписывания программы для новой, более перспективной архитектуры. Подобное удалось испытать тем, кто первоначально решал свои задачи на последовательных компьютерах, а затем перешел на одну их параллельных систем. Зачастую ранее используемые методы плохо поддаются распараллеливанию или не обеспечивают достижения требуемых критериев, например, погрешности вычислений. В таких случаях приходится создавать новые алгоритмы, адаптированные к специфике предоставляемых вычислительных ресурсов. В настоящее время существуют и используются разнообразные параллельные архитектуры. И хотя, на данный момент, популярностью пользуются одни из них, не факт, что через определенный период не произойдет смещение к широкому использованию другого, более удачливого конкурента. Следовательно, придется перерабатывать существующие вычислительные методы и алгоритмы.
Перспективной видится разработка программ для некоторой идеальной системы, которая позволила бы описывать алгоритмы в машинно-независимой форме, адаптируемой к конкретной вычислительной среде с помощью систем программирования. Один из вариантов, последовательное программирование, в свете выше названных причин не оправдал себя, что во многом обуславливается ограничениями, налагаемыми на алгоритм используемым методом управления вычислениями.
Рассмотрим альтернативный подход: разработку параллельных программ, обладающих максимальным параллелизмом. То есть, программ, не зависящих от ресурсных ограничений. Недостатки его непосредственного использования представлены в работе [1]. Там же отмечено, что последнее слово в работах по этому направлению не сказано. Как вариант развития данного подхода в работе предлагается использование сжатия максимального параллелизма с учетом налагаемых ресурсных и функциональных ограничений.
Такой способ создания программ чем-то напоминает нисходящее программирование. Но вместо постепенной детализации разрабатываемого алгоритма происходит аналогичное уточнение ограничений, накладываемых на параллелизм программы в соответствии со спецификой ее дальнейшего использования. В перспективе подобные преобразования можно проводить формально, опираясь на базу знаний и язык, допускающий эквивалентные преобразования исходной программы в соответствии с заложенными в него аксиомами и алгеброй преобразований, а также заменой эквивалентных по результатам функций, обладающих разным уровнем распараллеливания.
Основные идеи подхода ниже продемонстрированы на построении и преобразовании алгоритмов сортировки элементов вектора. Данный пример выбран исходя из общей известности методов сортировки и простоты понимания используемых при этом подходов. В принципе, ничто не мешает продемонстрировать предлагаемый подход и на других задачах.
Традиционный подход к алгоритмам сортировки
Сортировка – задача, хорошо исследованная в последовательном программировании. Предложено много методов и приемов, повышающих скорость получения результата. Поражает разнообразие существующих алгоритмов. Не менее впечатляющей выглядит и их эволюция, сопровождаемая постепенным накоплением разных эвристических приемов. Вот, например, один из списков методов сортировки, рассмотренных в классической книге Вирта [2]:
-
Сортировка с помощью прямого включения (Straight Insertion);
-
Сортировка методом деления пополам (Binary Insertion);
-
Сортировка с помощью прямого выбора (Straight Selection);
-
Сортировка с помощью прямого обмена (Bubble Sort);
-
Шейкерная сортировка (Shaker Sort);
-
Сортировка Шелла (Shell Sort);
-
Сортировка с помощью «дерева» (Heap Sort);
-
Сортировка с помощью разделения (Quick Sort);
-
Сортировка с помощью прямого слияния (Straight Merge);
Такое разнообразие методов затрудняет переход к параллельным реализациям. Еще менее понятно, каким образом эти алгоритмы будут вести себя на различных параллельных архитектурах. Нельзя сказать, что не существует эффективных решений, опирающихся на использование последовательных аналогов. Но они зачастую касаются использования конкретных алгоритмов в конкретных условиях [3].
Сортировка перебором
Если абстрагироваться от эффективности вычислительного процесса и обратить внимание только на обеспечение максимально параллельной сортировки, то можно прийти к следующему алгоритму, представленному в работе [3]:
-
Каждый элемент Ai вектора A[0..n-1] сравнивается со всеми другими (включая и себя) с использованием отношения:
(Ai > Aj) или ((Ai = Aj) и (i > j)).
Все проверки осуществляются одновременно.
-
Для всех элементов вектора одновременно подсчитывается количество истинных результатов сравнения с формированием вектора сумм в соответствии с расположением элементов.
-
Вектор сумм используется как набор индексов для одновременного размещения значений соответствующих ему элементов в новом векторе.
Пример, демонстрирующий использование данного алгоритма, приведен на рисунке 1. Значения элементов вектора заимствованы из [2].
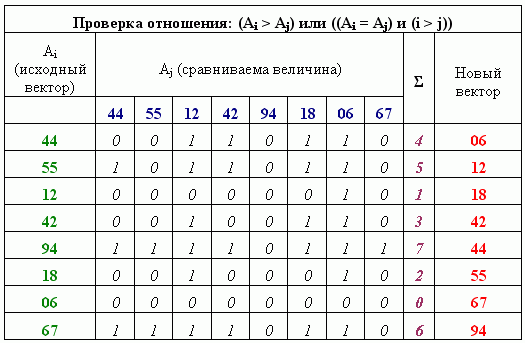
Рисунок 1 – Пример, демонстрирующий выполнение сортировки перебором
Изучение сортировки перебором позволяет наложить на нее некоторые ограничения, обеспечивающие переход к уже знакомым алгоритмам. При этом «сжатие параллелизма» также обеспечивает и «свертку» пространства возможных решений по сравнению с попытками найти их, двигаясь от последовательных сортировок. Остановимся на некоторых вариантах.
Сокращение числа операций сравнения
Один из путей связанных с повышением эффективности использования ресурсов может заключаться в удалении избыточных симметричных проверок. В частности, для получения результата достаточно осуществить сравнение только пар операндов, расположенных выше главной диагонали (рисунок 2). В этом случае количество проверок будет сопоставимым с их числом в простых последовательных алгоритмах (Straight Selection, Bubble Sort). Значения для отношений, определяемых главной диагональю, можно проставить без вычислений, Элементы, расположенные, ниже главной диагонали, можно вычислить путем отрицания результатов, симметрично расположенных выше нее. В связи с тем, что для элементов, расположенных выше главной диагонали, i всегда будет больше j, условие можно свести к проверке отношения Ai > Aj.
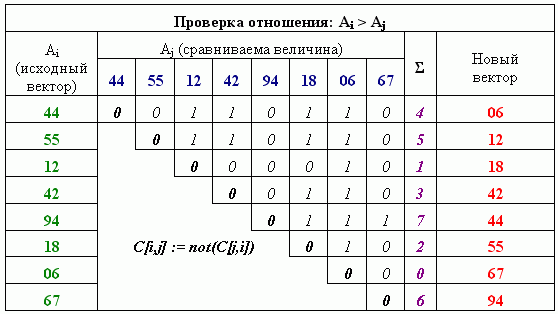
Рисунок 2 – Уменьшение количества одновременных проверок
Индексы, используемые для перестановки элементов, можно получить еще более простым способом. Нужно сложить (над главной диагональю) единицы в строке некоторого операнда с его же нулями в столбце. Подобная схема представлена на рисунке 3.
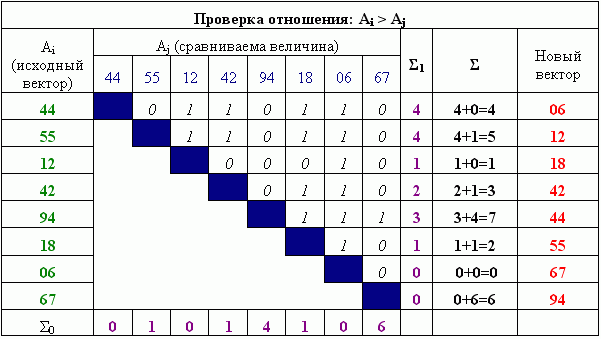
Рисунок 3 – Использование только половины сравнений для получения результата
Существуют и другие варианты формирования нового местоположения элемента. Например, можно вычислять новое положение элемента относительно текущей позиции. В этом случае индекс новой позиции формируется как сумма текущего положения и числа единиц по горизонтали, минус количество единиц по вертикали, на пересечении строки и столбца, для которых искомый элемент выступает в качестве первого и второго операнда одновременно (рисунок 4).
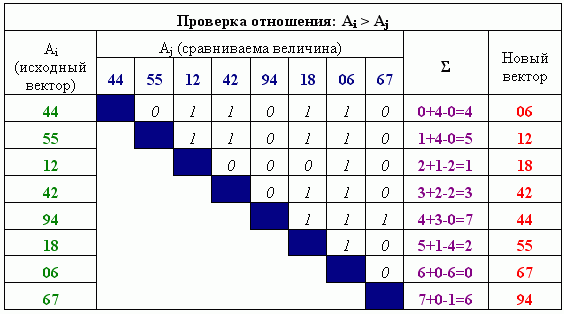
Рисунок 4 – Формирования индекса относительно текущего положения
Ограничение на количество сравниваемых первых операндов
Если разрешить за раз проводить сравнение только одного операнда со всеми остальными, то, вместо подсчета индекса, можно перейти к неупорядоченному перераспределению элементов относительно текущего (рисунок 5). Это ведет к одной из разновидностей алгоритма быстрой сортировки. Позиция элемента увеличивается на число истинных результатов сравнения. Элементы меньше первого операнда размещаются слева от него без изменения порядка следования относительно друг друга. Элементы, большие, чем первый операнд, аналогичным образом размещаются справа.
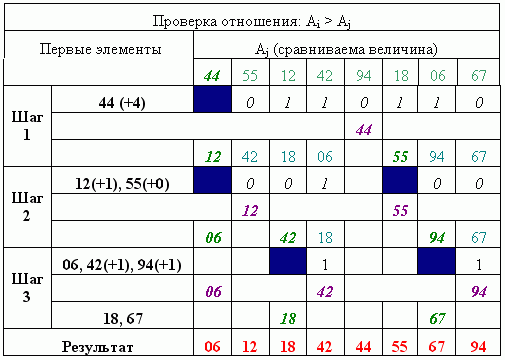
Рисунок 5 – Перераспределение относительно текущего элемента
Процесс сортировки рекурсивно повторяется, одновременно и асинхронно как для левой, так и для правой последовательности до тех пор, пока не будет получен окончательный результат.
Одновременное сравнение только с соседними элементами
Ограничения на допустимость проверки только с левым или правым соседом могут привести к построению пузырьковых алгоритмов. Подобные алгоритмы проще перекладывать на систолические архитектуры. Их анализ позволяет породить ряд специфических приемов.
Классическая схема получения результата с использованием сравнения всех соседних элементов представлена на рисунке 6. На нечетном шаге в качестве первых операндов используются элементы, стоящие на нечетном месте. На четном шаге – наоборот. Для данных, используемых в качестве примера, результат будет получен после выполнения семи шагов.
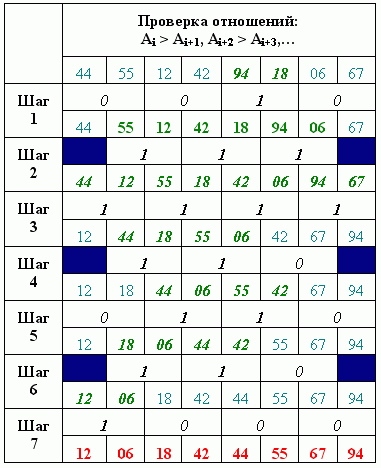
Рисунок 6 – Сортировка сравнением и обменом соседних элементов
Представленный способ можно улучшить, если осуществить одновременное сравнение каждого элемента массива с обоими соседями, а вместо перестановки пар осуществить обмен внутри группы элементов, расположенных по убыванию. Ее характерной чертой является наличие непрерывной подцепочки истинных результатов. Использование обмена, вместо парных перестановок позволяет, для представленного примера, получить результат за четыре шага (рисунок 7). Эффективность способа особенно заметная, если все элементы отсортированы в обратном порядке. В этом случае достаточно одного шага сравнений и обмена.
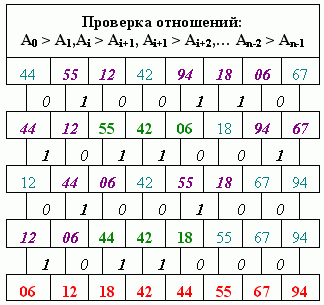
Рисунок 7 – Сортировка сравнением и обменом внутри последовательности,
расположенной в порядке убывания
Подобный подход может использоваться и в последовательных алгоритмах для улучшения простой пузырьковой сортировки.
Сортировки слиянием
Предыдущий алгоритм позволяет прийти к выводу о том, что внутри вектора формируются частичные подсписки с элементами, расположенными в порядке убывания или возрастания. Последние, путем обмена, легко сводятся с искомому отношению порядка. Однако для двух соседних упорядоченных подсписков использование парных перестановок становится неэффективным. Очевидно, что в этом случае лучше применить слияние.
Слияние тоже можно рассматривать как параллельный процесс и в общем случае можно реализовать как неограниченный алгоритм, аналогичный сортировке перебором:
-
Каждый элемент первого упорядоченного подсписка проверяется на отношение «больше» («>») со всеми элементами второго упорядоченного подсписка. Все проверки проводятся одновременно. Подсписки могут быт разной длины.
-
Для всех элементов первого подсписка одновременно подсчитывается количество истинных результатов сравнения, которые используются для смещения элементов вниз относительно своего текущего положения. Одновременно для всех элементов второго подсписка истинные результаты сравнения используются для подсчета смещений вверх.
-
Формируется вектор индексов используемый для одновременного размещения значений соответствующих ему элементов в новом векторе.
Пример использования этого алгоритма для частично упорядоченных векторов представлен на рисунке 8.
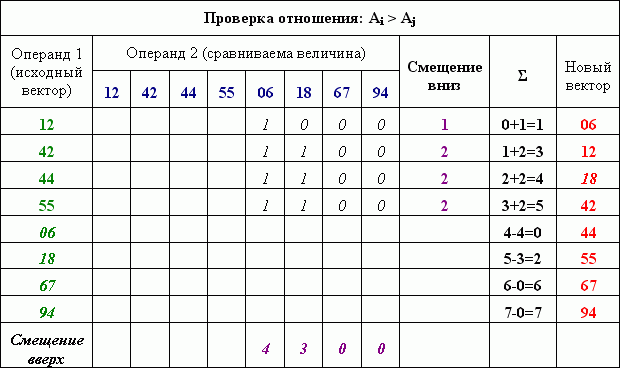
Рисунок 8 – Пример, демонстрирующий выполнение слияния перебором
Как и сортировка перебором, слияние перебором может использоваться для построения алгоритмов с ограниченным параллелизмом по схемам, описанным выше.
Сама сортировка слиянием протекает как рекуррентный процесс, в котором на первом шаге отдельные соседние элементы одновременно сливаются в пары, затем пары сливаются в четверки и т.д. На рисунке 9 показано, что сортировка слиянием, для рассматриваемого набора данных выполняется за три шага.
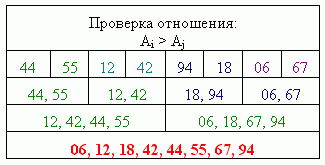
Рисунок 9 – Сортировка слиянием
Заключение
Использование алгоритмов, описывающих максимальный параллелизм решаемой задачи, предоставляет в распоряжение разработчика дополнительные методы для анализа и вывода разнообразных алгоритмов с ограниченным параллелизмом, которые могут рассматриваться как варианты использования. Наложение дальнейших ограничений позволяет создавать не только параллельные, но и последовательные программы. В зависимости от неоднородности архитектуры параллельной вычислительной системы можно использовать различные комбинации ограниченных алгоритмов, наиболее эффективные на соответствующих уровнях иерархии. Допустимы также ограничения на использование памяти, потоков ввода-вывода и др. Помимо этого, доказательство корректности максимально параллельного алгоритма и использование формальных преобразований к ограниченным его формам позволяет автоматически переносить доказательство корректности и на них.
Подход позволяет перейти к построению высокоэффективных программ, предназначенных для конкретных архитектур. Для этого необходимо согласованием между ресурсными ограничениями вычислительной систмы и ограничениями, накладываемыми на программу, изначально обладающую максимальным параллелизмом.
Работа выполнена при поддержке РФФИ № 02-07-90135.
Примечание. Материал первоначально представлен в докладе, на 3-м семинаре «Распределенные и кластерные вычисления», Красноярск, сентябрь 2003 [4].
Список литературы
-
Воеводин В.В., Воеводин Вл.В. Параллельные вычисления. – СПб.: БХВ-Петербург, 2002. – 608 с.
-
Вирт Н. Алгоритмы и структуры данных. - М.: Мир, 1989. – 360 с.
-
Grama A., Gupta A., Karypis G., Kumar V. Introduction to Parallel Computing, Second Edition. – Addison Wesley, 2003. 856 pp.
-
Легалов А.И. Методы сортировки, полученные из анализа максимально параллельной программы. – Распределенные и кластерные вычисления. Избранные материалы Третьей школы-семинара. / Институт вычислительного моделирования СО РАН. Красноярск, 2004, с. 119-134.
|