[
содержание
| предыдущая тема
| следующая тема
]
Содержание темы
Транслитератор DPL. Непрямой лексический анализатор DPL. Прямой лексический анализатор DPL.
Отсюда можно скачать исходные тексты непрямого и прямого лексических анализаторов
демонстрационного языка программирования.
Транслитератор DPL
Общая организация транслитератора
Транслитератор демонстрационного языка программирования используется для выделения следующих классов отдельных символов:
Класс букв: содержит прописные и строчные буквы латинского алфавита, используемые при создании разнообразных конструкций языка. Русские буквы в этот класс не включаются, так как используются только внутри строк и комментариев, допускающих почти все символы.
Класс десятичных цифр: объединяет арабские цифры от 0 до 9. Используется при формировании описаний действительных, а также некоторых из целых чисел.
Класс двоичных цифр: объединяет цифры 0 и 1. Используется при анализе целых двоичных чисел.
Класс восьмеричных цифр: объединяет цифры от 0 до 7. Используется при анализе целых восьмеричных чисел.
Класс шестнадцатеричных цифр: включает цифры от 0 до 9, а также прописные и строчные буквы: A, B, C, D, E, F, a, b, c, d, e f.
Класс пропусков: состоит из пробела, перевода строки, табуляции, перевода формата (разделяющего текст на отдельные страницы). Символы этого класса используются для разделения различных элементарных конструкций, слитное написание которых привело бы к неправильному восприятию (например, следующие друг за другом число и идентификатор "123E4 asdf" без пробела были бы восприняты как "123E4asdf", что является ошибкой).
Класс игнорируемых символов: включает все символы, которые, как предполагается, не отображаются на экране текстового редактора. В используемых кодовых таблицах к ним относятся символы, коды которых меньше кода пробела. Исключение составляют перевод строки, табуляция, перевод формата, уже отнесенные к предыдущему классу. В некоторых текстовых редакторов данные символы отображаются в виде специальных значков. Поэтому, выделение данного класса может являться спорным и зависит от различных факторов.
Класс прочих символов: включает все оставшиеся символы. Не смотря на то, что их тоже можно группировать в различные классы, в рассматриваемом языке нам, в большинстве ситуаций, достаточно использовать их непосредственные значения
Следует отметить, что классы символов пресекаются. Однако, вопрос принадлежности нужному классу можно решать, основываясь на текущем контексте. Класс символов можно специально не хранить, а проверять тогда, когда потребуется.
Программная реализация транслитератора
Реализация транслитератора, как и любого другого программного модуля, во многом зависит от стиля программирования. Несмотря на простоту, эта задача может быть рассмотрена и в более широком контексте. Транслитератор можно использовать как совокупность нескольких функций, проверяющих принадлежность символа к одному из классов. Такая реализация выглядит вполне логичной при процедурном программировании. Вместе с тем следует отметить, что транслитератор не используется сам по себе. Он является промежуточным звеном между функциями, обеспечивающими чтение символов из входного потока и лексическим анализатором. Это промежуточное звено обычно скрывает от лексического анализатора механизм чтения и преобразования символов. Сканеру так же ничего не надо знать об открытии входного потока и манипуляции с ним. Поэтому, при объектно-ориентированном подходе, получение значение нового символа, его класса, а также манипуляция входным потоком реализуются как единый объект (на основе класса). Этот класс инкапсулирует внутренние операции, а также объединяет разбросанные по программе структуры данных, используемые для ввода символов и их преобразования.
Примечание. Одной из проблем, которая встала передо мной при подготовке данной темы, явилась проблема выбора реализации для демонстрационного примера. Что показать: простой по исполнению модуль сканера, построенный с использованием процедурного программирования, или его объектно-ориентированный аналог со всевозможными "наворотами"? Оба варианта я использовал при решении различных задач, поэтому проблем с самим кодом не было. Раздираемый мучительными противоречиями, я решил остановиться на процедурной версии в надежде на светлое будущее, в котором постараюсь добавить ОО реализацию в виде отдельного материала. В данном случае победило стремление к простоте представления материала. Не всех интересует объектно-ориентированное программирование (да и нужно ли оно?:-), а процедурное программирование (ПП) изучают практически все. Кроме того, я постарался скомпоновать модуль сканера таким образом, чтобы ОО гурманы могли легко переделать его в классы.
В результате этого решения, транслитератор оказался представлен следующим кодом:
// Функции транслитератора, используемые для определения класса лексем
//
// Определяет принадлежность символа к классу букв
bool inline isLetter(int ch) {
if((ch>='A' && ch<='Z') || (ch>='a' && ch<='z'))
return true;
else
return false;
}
//
// Определяет принадлежность символа к классу двоичных цифр
bool inline isBin(int ch) {
if((ch=='0' || ch=='1'))
return true;
else
return false;
}
//
// Определяет принадлежность символа к классу восьмеричных цифр
bool inline isOctal(int ch) {
if((ch >= '0' && ch <= '7'))
return true;
else
return false;
}
//
// Определяет принадлежность символа к классу десятичных цифр
bool inline isDigit(int ch) {
if((ch >= '0' && ch <= '9'))
return true;
else
return false;
}
//
// Определяет принадлежность символа к классу шестнадцатеричных цифр
bool inline isHex(int ch) {
if((ch >= '0' && ch <= '9') ||
(ch >= 'A' && ch <= 'F') ||
(ch >= 'a' && ch <= 'f'))
return true;
else
return false;
}
//
// Определяет принадлежность символа к классу пропусков
bool inline isSkip(int ch) {
if(ch == ' ' || ch == '\t' || ch == '\n' || ch == '\f')
return true;
else
return false;
}
//
// Определяет принадлежность к классу игнорируемых символов
bool inline isIgnore(int ch) {
if(ch>0 && ch<' ' && ch!='\t' && ch!='\n' && ch!='\f')
return true;
else
return false;
}
//
// Читает следующий символ из входного потока
static void nxsi(void) {
if((si = getc(infil)) == '\n') {
++line; column = 0;
} else {
++column;
}
++poz; // Переход к следующей позиции в файле
}
При использовании объектно-ориентированного подхода все эти данные можно инкапсулировать в один класс, обеспечив доступ к ним через соответствующий интерфейс. Следует также отдельно отметить последнюю строку функции nxsi():
++poz; // Переход к следующей позиции в файле
Она присутствует только в непрямом лексическом анализаторе и предназначена для фиксации позиции в файле, что позволяет осуществлять откаты назад в том случае, если проверяемая версия о значении лексемы не подтвердится. Взятие следующего символа в прямом сканере происходит без использования этого "довеска".
Непрямой лексический анализатор DPL
Непрямой
лексический анализатор, в
соответствии с ранее описанной
теорией, реализуется как
совокупность независимых конечных
автоматов, проверяющих
принадлежность к отдельным
лексемам. А эти автоматы, как было
показано ранее, можно описать с
использованием диаграмм Вирта.
Практическая же целесообразность
диктует следующие, используемые
мною, технические решения:
Конечный автомат,
осуществляющий распознавание
одной конкретной лексемы, может
быть разбит на несколько, более
мелких автоматов, каждый из которых
распознает непересекающееся
подмножество цепочек,
принадлежащих искомому классу.
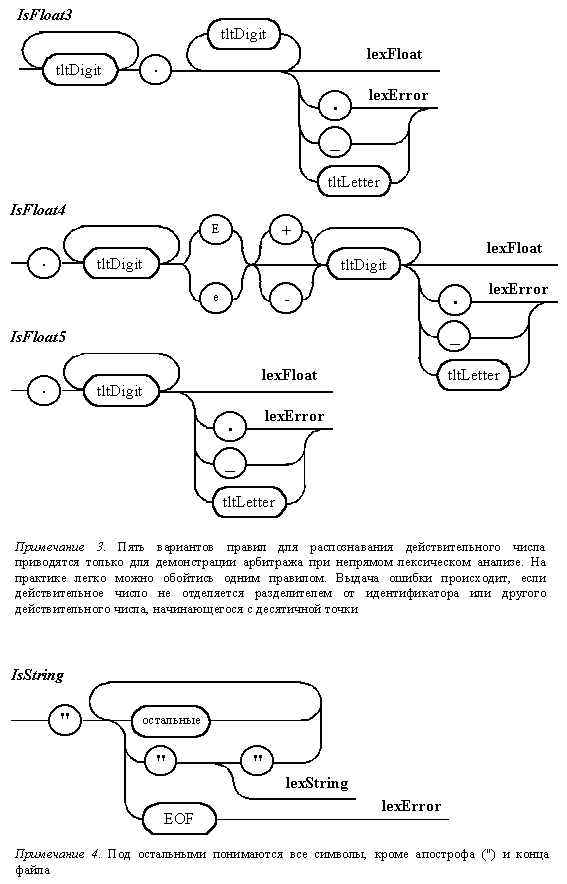
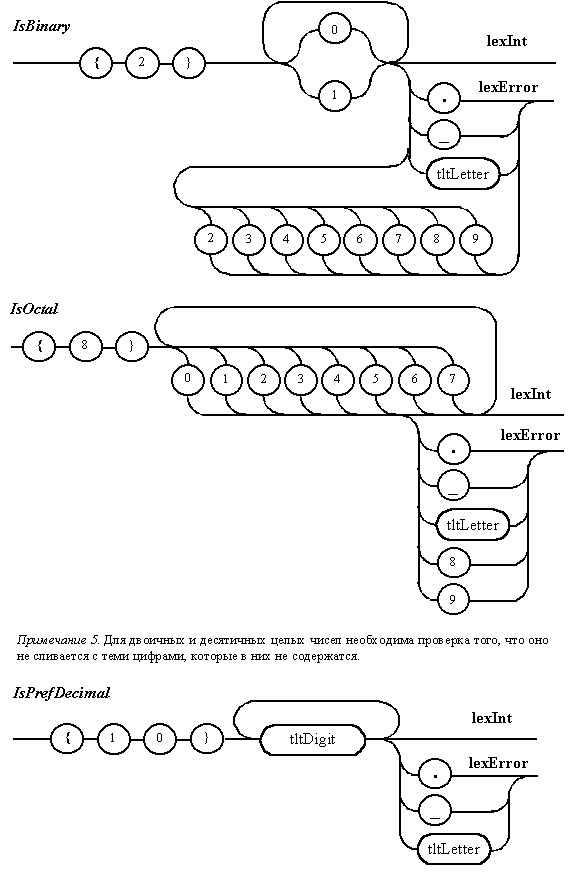
Например, при распознавании целого
числа можно построить отдельные
автоматы для выявления двоичных,
восьмеричных, десятичных,
десятичных с префиксом и
шестнадцатеричных чисел. Это
упрощает реализацию отдельных
автоматов. Для упрощения
реализации можно также
осуществлять создание автоматов,
распознающих цепочки, являющиеся
подцепочками других автоматов. В
этом случае необходимо таким
образом строить арбитраж, чтобы
распознавание более длинных
цепочек осуществлялось раньше. В
качестве примера, я искусственно
разбил распознаватель
действительного числа аж на пять
автоматов. Конечно, в реальной
ситуации, "дробить" таким
образом действительное число вряд
ли имеет смысл. Однако трудно было
удержаться от искушения и не
продемонстрировать один из
технических приемов.
Автоматы можно не
только разделять, но и объединять,
что ведет к использованию
фрагментов прямого лексического
анализа. Оставим эту технику для
прямого лексического анализатора.
Можно также
использовать и семантический
анализ, что позволяет сократить код
и ускорить разбор. На рис. 5.1а показан возможный
вариант разбора ключевых слов.
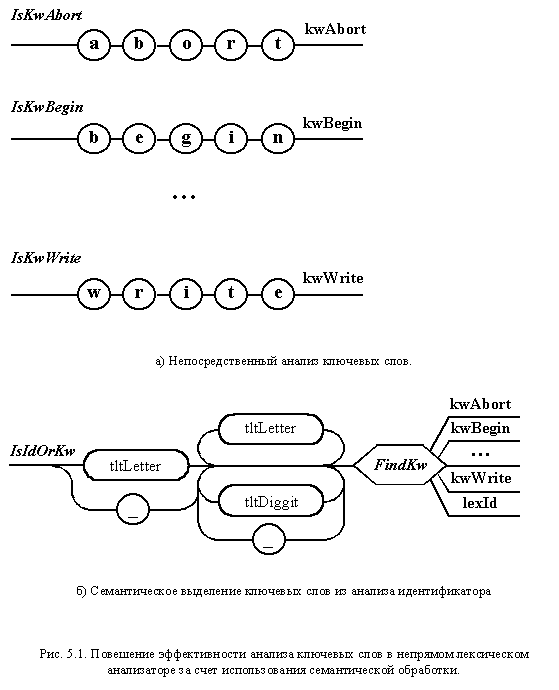
Для распознавания
каждого ключевого слова можно
построить свой автомат. В этом
случае возникает несколько проблем:
- замедляется
разбор, что связано с
постоянными откатами,
используемыми в непрямом
лексическом анализаторе (чем
больше автоматов, тем
медленнее разбор, а ключевых
слов может быть много);
- состав
ключевых слов может постоянно
меняться (особенно, в новом
языке), что ведет к
необходимости модификации
кода программы.
Гораздо проще и
быстрее провести распознавание
ключевых слов с использованием
семантической обработки. Чаще
всего (а в данном случае - это факт)
ключевые слова являются
подмножеством идентификаторов.
Поэтому, можно в начале осуществить
выявление идентификатора, а затем
провести его анализ на
принадлежность к ключевому слову.
Такой анализ можно осуществлять
поиском (лучше всего двоичным)
значения полученного
идентификатора в таблице ключевых
слов. При обнаружении совпадения
формируется лексема,
соответствующая выявленному
ключевому слову. В противном случае
выдается лексема - идентификатор.
Соответствующая этому случаю
диаграмма Вирта, вместе с блоком
семантического разбора (представленного
шестиугольником) приведена на рис.
5.1б. Аналогичную
схему имеет смысл использовать и в
прямом лексическом анализаторе.
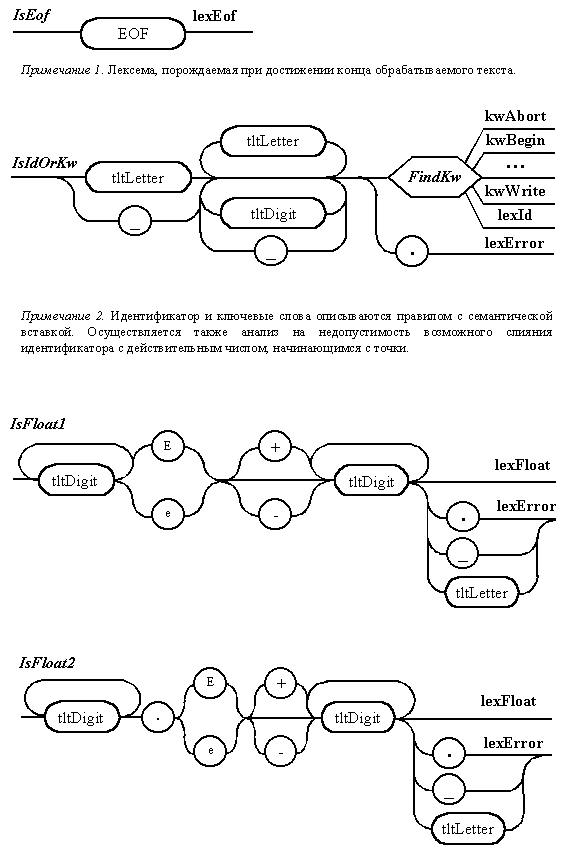
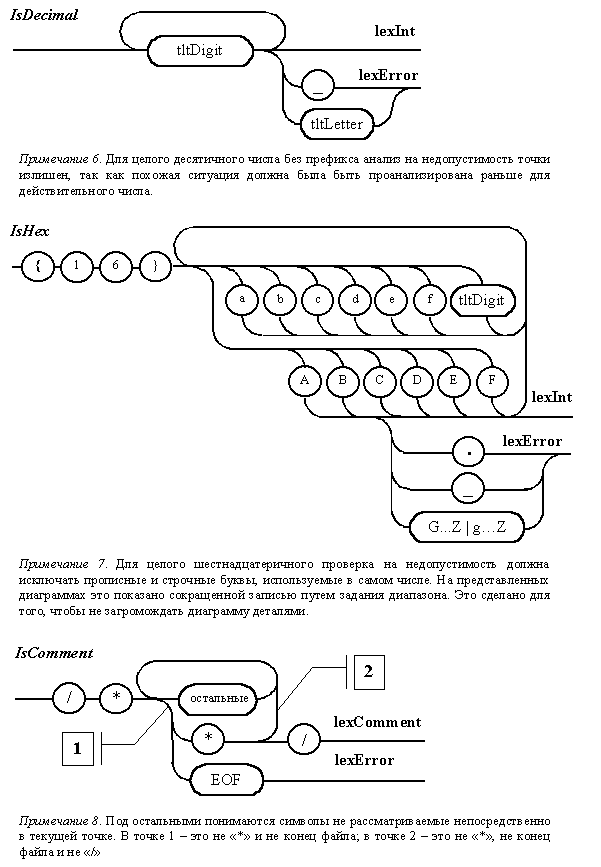
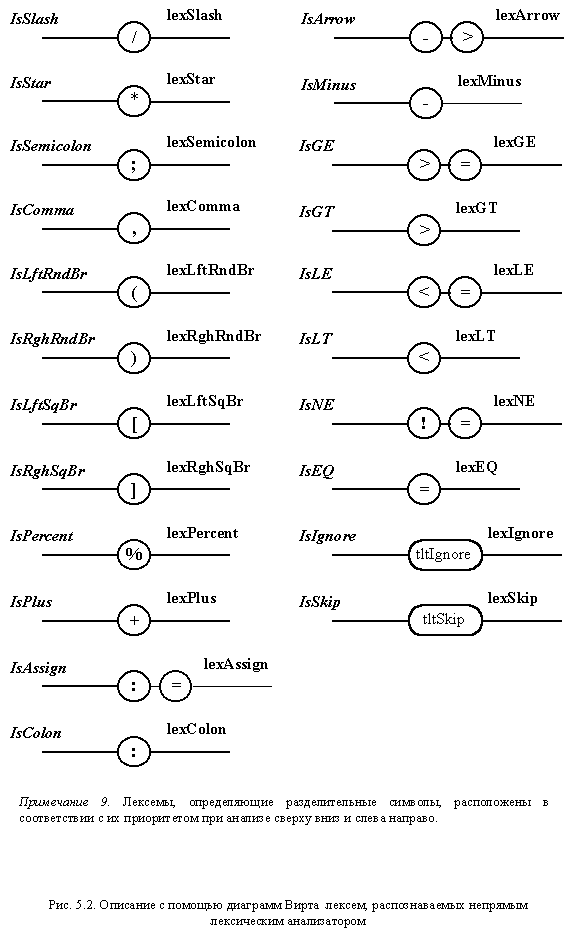
Диаграммы Вирта
для отдельных автоматов непрямого
лексического анализатора
Диаграммы Вирта,
описывающие отдельные независимые
фрагменты непрямого лексического
анализатора, представлены на рис.
5.2. В отличие от
диаграмм, используемых для
описания пользовательского
синтаксиса, данные схемы помечены
именами, которые предполагается
использовать в программе. Выходы
диаграмм идентифицируют
порождаемые лексемы. Каждая из
диаграмм непосредственно не
связана с механизмом отката. Этим
занимается сам анализатор.
Программная
реализация отдельных автоматов
Каждый автомат
представлен соответствующей
процедурой (функцией),
осуществляющей имитацию переходов
от начального состояния к одному из
заключительных. Разметка диаграмм
Вирта, соответствующая состояниям
конечного автомата, была описана
ранее. Принципы программной
реализации в общем случае тоже
достаточно просты:
- каждому
состоянию ставится в
соответствие метка;
- анализируемые
альтернативы проверяются
условными операторами (на мой
взгляд, они подходят лучше
переключателей из-за того, что
проверяться могут значения
символов и их классы);
- если результат
проверки является истиной,
проводится обработка
контекста, берется следующий
символ и осуществляется
переход на новую метку (в новое
состояние);
- процесс
повторяется до тех пор, пока не
произойдет переход в одно
заключительных состояний.
Да, Вы правы, я без
зазрения совести использую
операторы безусловного перехода! И
это после работы Дейкстры,
заклеймившей goto!! Как можно
посягать на каноны
программирования, когда в
современных языках этот оператор
просто не существует!!! А ведь Вы еще
не видели программной реализации
диаграмм, используемых в
синтаксическом анализаторе!!!! Я не
собираюсь с пеной у рта отстаивать
используемое решение, но робко
мотивировать его все же попробую.
Во-первых,
основным документом, по которому
разрабатываются программные
модули, является диаграмма Вирта,
которая, в общем случае является
неструктурированным графом. А
такие графы невозможно представить
без goto, если только не осуществить
соответствующие преобразования.
Применение же этих преобразований
может снизить наглядность исходных
диаграмм, привести к их
избыточности, что ведет к
соответствующему "захламлению"
и формируемого кода. Тогда проще
сразу отказаться от диаграмм Вирта
и перейти на РБНФ. Именно
неструктурированные диаграммы
Вирта диктуют мне ранее описанную
регулярную схему моделирования
каждой ее отдельной связи.
Во-вторых,
используя данный подход, можно, с
помощью экранного редактора,
достаточно быстро набирать
фрагменты новых правил, перенося
отдельные связи из ранее набранных
диаграмм. Особенно удобно такое
редактирование при написании
синтаксического анализатора.
В третьих,
достаточно часто мне приходилось
заниматься разработкой новых
языков программирования, синтаксис
которых изменялся уже во время
написания программы. При
использовании goto модификация
связей диаграммы достаточно просто
отображалась на изменение
программного кода. Кроме того,
изменение диаграмм возможно и при
разработке трансляторов с уже
существующих языков. Это, например,
может быть связано со стремлением
преобразовать грамматику к
определенному виду.
В четвертых,
формируемые синтаксические
правила обычно порождают небольшой
код, большая часть которого
размещается в пределах страницы (экрана).
Его достаточно легко охватить
единым взором и сопоставить с
нарисованной диаграммой. Поэтому,
на мой взгляд, нагромождение
операторов безусловного перехода в
глаза особо не бросается. :-)
В пятых, одно
время я увлеченно прорабатывал
средства визуальной разработки
трансляторов. А для таких средств
особого значения не имеет вид
выходного представления.
Представленный выше метод
порождения кода достаточно легко
ложился на разрабатываемые
структуры. Проект умер, а goto
остались.
В шестых, даже
Дональд Кнут указывал на
полезность goto в ряде случаев (статья:
Structured programming with GOTO statements. ACM Computing
Surveys, 6, №4, 1974). Почему же мне не
использовать его в том случае,
когда код функции изначально может
быть неструктурным?
Уф! Столько
оправданий из-за какого-то
маленького оператора! Надеюсь, что
с Дейкстрой разобрался. Кто
следующий? Гради Буч?! Я считаю, что все выше
сказанное поясняет, почему я не
считаю языками программирования те
из них, в которых отсутствует GOTO.
Еще лучше, если используется
управляющий оператор перехода, как
в Фортране, или
переменные-метки, как в PL/1. :(Ой!
Больно! Уж и пошутить нельзя!:)
Ну а если серьезно,
то каждый эволюционно вырабатывает свой
стиль (о вкусах не спорят) или, при
работе в коллективе, адаптируется к
принятым групповым требованиям
(в чужой монастырь...).
Такова жизнь!
Общая структура
непрямого лексического
анализатора
В завершение
всего можно привести объединенную
диаграмму Вирта, определяющую
взаимосвязи между отдельными,
ранее представленными автоматами (рис.
5.3). На ней
отражается альтернативный порядок
следования разбираемых лексем с
учетом приоритетов, определяемых
схемой арбитража.
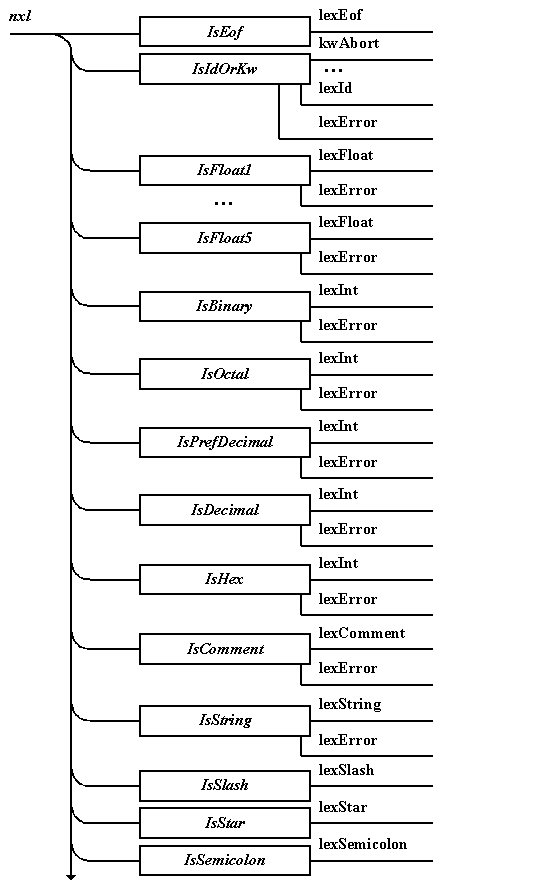
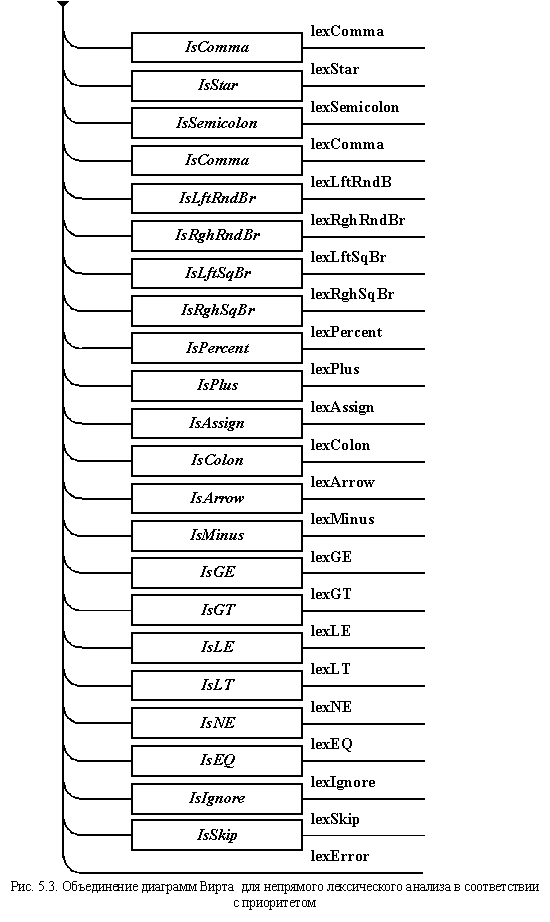
В основной
программе данной диаграмме
соответствует функция nxl(),
порождающая лексемы.
//-------------------------------------------------------------------
// Функция, формирующая следующую лексему
// Вызывается синтаксическим анализатором
//-------------------------------------------------------------------
void nxl(void) {
do {
i_lv = -1;
lv[0] = '\0';
// Фиксируем начальную позицию
oldpoz=ftell(infil)-1;
oldline=line; oldcolumn=column;
// Процесс пошел
if(si == EOF) {lc = lexEof; return;}
// Игнорируемую лексему не возвращаем
if(isSkip(si)) {nxsi(); lc = lexSkip; continue; /*return;*/}
if(id_etc()) {return;} unset();
if(string_const()) {return;} unset();
if(float1()) {return;} unset();
if(float2()) {return;} unset();
if(float3()) {return;} unset();
if(float4()) {return;} unset();
if(float5()) {return;} unset();
if(binary()) {return;} unset();
if(octal()) {return;} unset();
if(hex()) {return;} unset();
if(pdecimal()) {return;} unset();
if(decimal()) {return;} unset();
// Игнорируемую лексему не возвращаем
if(comment()) {continue; /*return;*/} unset();
// Игнорируемую лексему не возвращаем
if(isIgnore(si)) {nxsi(); lc = lexIgnore; continue; /*return;*/}
if(si=='/') {nxsi(); lc = lexSlash;return;}
if(si == ';') {nxsi(); lc = lexSemicolon; return;}
if(si == ',') {nxsi(); lc = lexComma; return;}
if(si == ':') {
nxsi();
if(si == '=') {nxsi(); lc = lexAssign; return;}
} unset();
if(si==':') {nxsi(); lc = lexColon; return;}
if(si == '(') {nxsi(); lc = lexLftRndBr; return;}
if(si == ')') {nxsi(); lc = lexRghRndBr; return;}
if(si == '[') {nxsi(); lc = lexLftSqBr; return;}
if(si == ']') {nxsi(); lc = lexRghSqBr; return;}
if(si == '*') {nxsi(); lc = lexStar; return;}
if(si == '%') {nxsi(); lc = lexPercent; return;}
if(si == '+') {nxsi(); lc = lexPlus; return;}
if(si == '-') {
nxsi();
if(si == '>') {nxsi(); lc = lexArrow; return;}
} unset();
if(si=='-') {nxsi(); lc=lexMinus; return;}
if(si == '=') {nxsi(); lc = lexEQ; return;}
if(si == '!') {
nxsi();
if(si == '=') {nxsi(); lc = lexNE; return;}
} unset();
if(si == '>') {
nxsi();
if(si == '=') {nxsi(); lc = lexGE; return;}
} unset();
if(si=='>') {nxsi(); lc=lexGT; return;}
if(si == '<') {
nxsi();
if(si == '=') {nxsi(); lc = lexLE; return;}
} unset();
if(si=='<') {nxsi(); lc=lexLT; return;}
lc = lexError; er(0); nxsi();
} while (lc == lexComment || lc == lexSkip || lc == lexIgnore);
}
Остановимся на
ряде моментов. В сканер введен цикл,
который отфильтровывает лексемы,
не обрабатываемые распознавателем.
Это комментарии, пропуски,
игнорируемые символы.
Для выполнения
отката, в начале обработки лексемы
запоминаются текущие позиции в
файле, строке и столбце. При неудаче
они восстанавливаются и происходит
анализ следующей диаграммы.
Функция отката unset() реализована
следующим образом:
// откат назад при неудачной попытке распознать лексему
static void unset() {
fseek(infil, oldpoz, 0);
nxsi();
i_lv=-1;
lv[0]='\0';
poz = oldpoz;
line=oldline;
column=oldcolumn;
}
Вот, в общем-то, и
все. С реализацией отдельных
диаграмм, процедурой обработки
ошибок и тестовыми процедурами
можно ознакомиться по
представленным примерам.
Прямой
лексический анализатор DPL
При разработке
прямого лексического анализатора
поступают очень просто: все правила,
используемые в этой фазе, сваливают
в одну кучу, после чего начинается
их группировка по группам,
начинающихся с одинаковых
начальных символов. Эти символы
образуют набор альтернатив,
анализируемых на первом шаге или,
что одно и тоже из начального
состояния единого и плоского
конечного автомата. Далее,
аналогичный анализ осуществляется
в каждой из подгрупп. При этом,
достаточно длинные правила можно
оформлять как отдельные автоматы,
что, в конце концов, приведет в
созданию соответствующих процедур.
Сформированный общий автомат,
обеспечивающий прямой лексический
анализ (представленный диаграммой
Вирта), приведен на рис. 5.4.
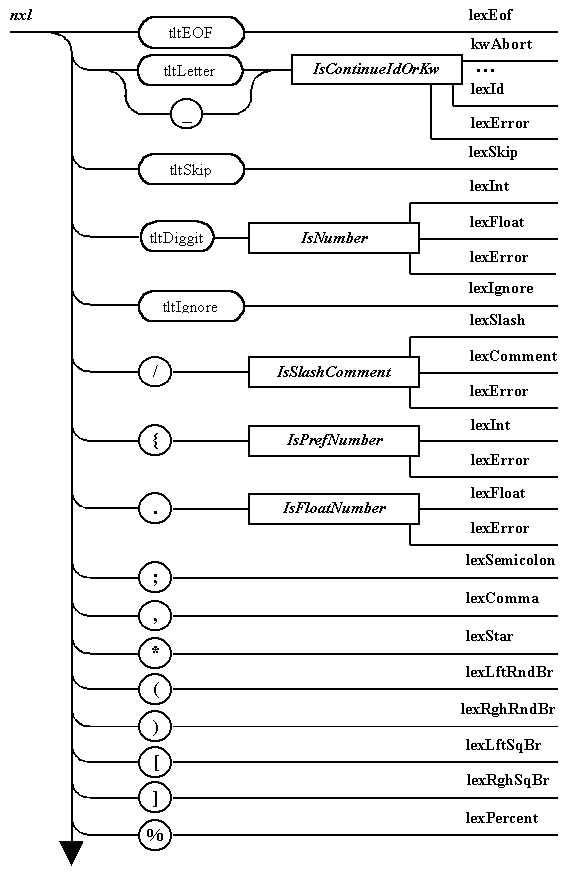
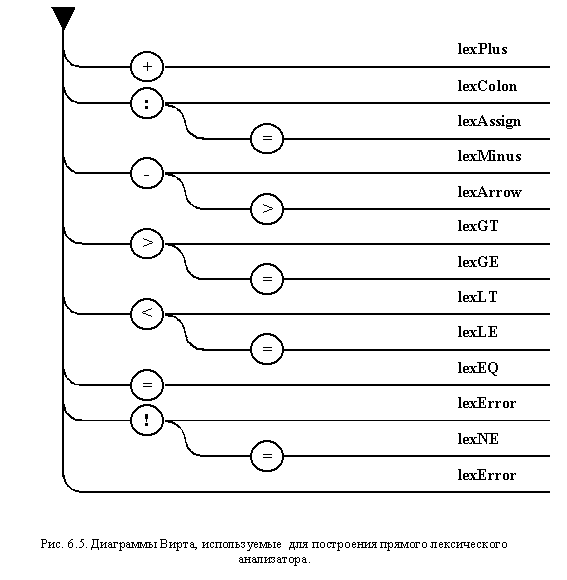
Программная
реализация функции, реализующей
этот замысел, выглядит следующим
образом.
//--------------------------------------------------------------------
// Функция, формирующая следующую лексему
// Вызывается синтаксическим анализатором
//--------------------------------------------------------------------
void nxl(void) {
do {
i_lv = -1;
lv[0] = '\0';
if(si == EOF) {lc = lexEof;}
else if(isSkip(si)) {nxsi(); lc = lexSkip;}
else if(isLetter(si) || si == '_'){
lv[++i_lv]=si; nxsi(); id_etc();
}
else if(isDigit(si)) {number();}
else if(isIgnore(si)) {nxsi(); lc = lexIgnore;}
else if(si == '/') {nxsi(); divcom();}
else if(si == '\"') {nxsi(); string_const();}
else if(si == ';') {nxsi(); lc = lexSemicolon;}
else if(si == ',') {nxsi(); lc = lexComma;}
else if(si == ':') {
nxsi();
if(si == '=') {nxsi(); lc = lexAssign;}
else lc = lexColon;
}
else if(si == '(') {nxsi(); lc = lexLftRndBr;}
else if(si == ')') {nxsi(); lc = lexRghRndBr;}
else if(si == '[') {nxsi(); lc = lexLftSqBr;}
else if(si == ']') {nxsi(); lc = lexRghSqBr;}
else if(si == '*') {nxsi(); lc = lexStar;}
else if(si == '%') {nxsi(); lc = lexPercent;}
else if(si == '+') {nxsi(); lc = lexPlus;}
else if(si == '-') {
nxsi();
if(si == '>') {nxsi(); lc = lexArrow;}
else lc = lexMinus;
}
else if(si == '=') {nxsi(); lc = lexEQ;}
else if(si == '!') {
nxsi();
if(si == '=') {nxsi(); lc = lexNE;}
else {lc = lexError; er(1);}
}
else if(si == '>') {
nxsi();
if(si == '=') {nxsi(); lc = lexGE;}
lc = lexGT;
}
else if(si == '<') {
nxsi();
if(si == '=') {nxsi(); lc = lexLE;}
lc = lexLT;
}
else if(si == '{') {nxsi(); prenumber();}
else if(si == '.') {lv[++i_lv]=si; nxsi(); fltnumber2();}
else {lc = lexError; er(0); nxsi();}
} while (lc == lexComment || lc == lexSkip || lc == lexIgnore);
}
Напоминаю, что при
взятии для анализа и
транслитерации следующего символа,
не надо учитывать позицию в файле.
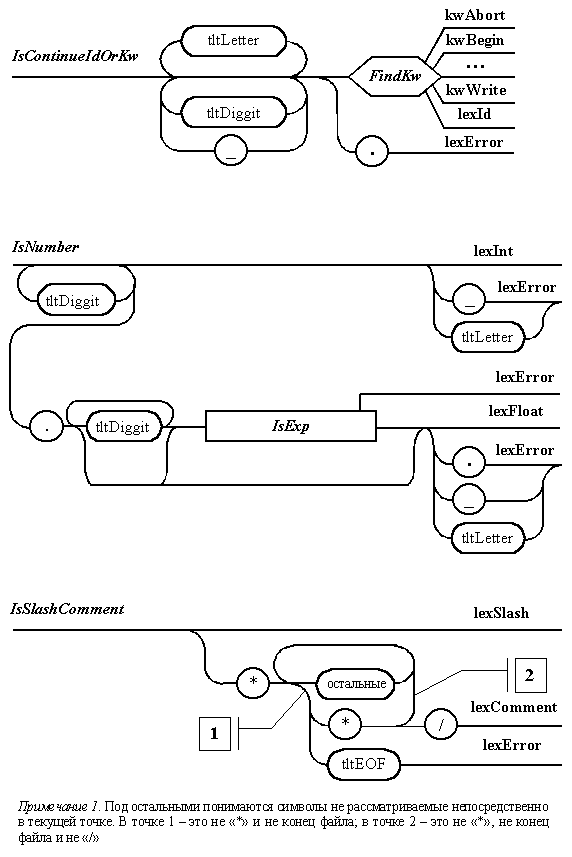
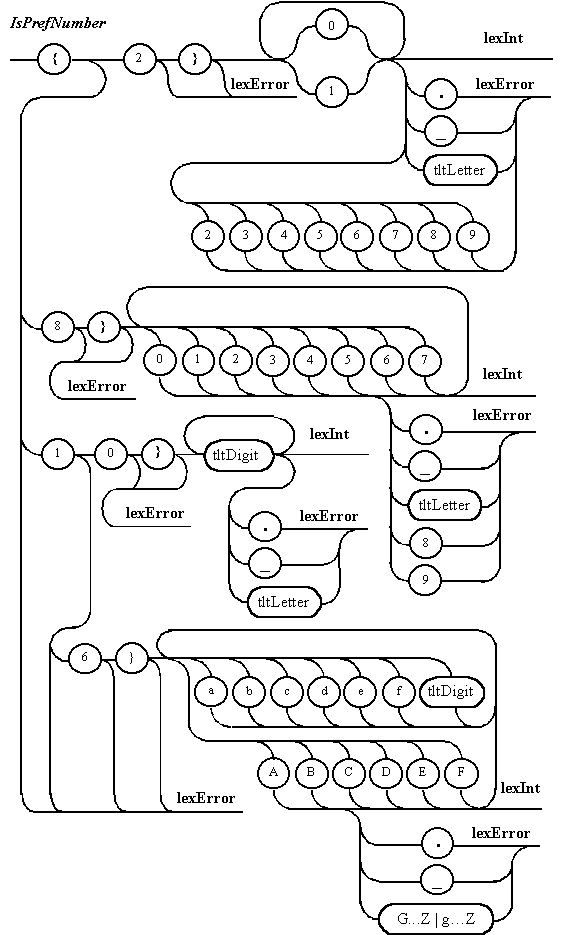
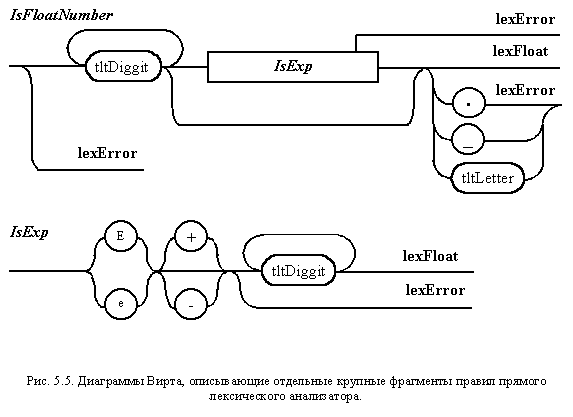
Диаграммы Вирта,
описывающие отдельные подавтоматы
прямого лексического анализатора,
представлены на рис. 5.5. Их программную
реализацию проще всего изучить на
предлагаемых для загрузки исходных
текстах
Контрольные вопросы и задания
- Разработать лексический анализатор в соответствии
с вариантом задания, полученным для выполнения лабораторных работ.
[
содержание
| предыдущая тема
| следующая тема
]
|