© Борис Кузнецов (Санкт-Петербург, 1992)
Предисловие
Когда-то автор был руководителем разработок в области автоматизированного проектирования и автоматизизации программирования. Объекты разработок были самые разнообразные, приходилось детально вникать в суть решаемых задач, создавать подробные спецификации, в том числе различныз баз и структур данных и как укрупненные так и детальные алгоритмы, а также коды критических фрагментов или целых программ. Коллектив был разношерстный и веселый - работать было интересно и перспективно и с удовлетворением от внедрения. Были и неизбежные промашки. В общем кипела жизнь. Но в ходе перестройки автор вынужден был остаться один на один в руководимом им подразделении, сведенному к единственному сотруднику и начальнику в одном лице, с полученной по согласованной инициативе с основным заказчиком работой, называемой транслятором для дешевого но полнофункционального контроллера с хитрой системой команд и оригинальной архитектуры. Автор посоветовавшись с основным заказчиком решил и создал в черновиках спецификации полнофункционального транслятора на ограниченном клоне языка С ("Программист" 2002 №3 с.17-22) . Одновременно любительски осваивался ПК, С++ и среда программирования С++. Создавая на ходу открытую проектную документацию в виде рабочих черновиков с графикой таблицами и текстами, автор все-таки создал транслятор и передал его в долгосрочную эксплуатацию, не получившую рекламаций со стороны основного заказчика и его же как пользователя с оригинальным именем Светлан Борисович (СБ), известным как крупный специалист в ряде стран. Другой неожиданный пользователь, делавший с помощью транслятора ПИД-регуляторы, правда нашел вполне исправимые глюки. Впоследствии транслятор был дополнен реализацией макрорасширений по рекомендации и просьбе СБ (в контроллере изготовитель расширил систему команд). Транслятор был передан изготовителю контроллера, а также его представителю по продажам в Москве, за что было получено некоторое вознаграждение, позволившее заменить домашние Celeron и видеоплату на их модификации.
При разработке транслятора автор поставил цель - не повторять то что пишут в книгах про трансляцию, так как результат получился бы громоздким, и создать возможности для попутной оптимизации кода-результата трансляции как по длине и быстродействию так и, например, по использованию стека. Вот один из зигзагов проектирования транслятора и представляется на суд читателей.
Трансляция логических выражений осуществляется без использования рекурсии, не зависит от числа компонент и структуры транслируемого выражения и реализуется фиксированным числом шагов. При этом каждый шаг является прямым или обратным просмотром выражения с добавлением или исключением его компонент.
Автор будет признателен за ссылки на оригинальные разработки трансляции логических выражений, созданные за последние 14 лет.
Если будут пожелания, то можно предъявить и рабочий код исходников.
В традиционных трансляторах принято использовать польскую запись или триады для получения кода логического выражения. В этих случаях не представляется возможным оптимизировать код логического выражения путем перестановок членов скобочной структуры. Кроме того, при использовании указанных структур зависимость длительности трансляции от числа символов в формуле оценивается нелинейно. Автор поставил целью создать алгоритм трансляции с линейной сложностью и допускающий возможность оптимизации кода логического выражения (путем целенаправленной перестановки членов формулы) по представленным ранее критериям (число путей в программном фрагменте, длительность вычисления или достоверность значения логической функции – см. статью «Модели конечных автоматов в виде булевых формул и их оптимизация», - а также размер стека промежуточных переменных) на этапе трансляции.
В основу алгоритма трансляции логического выражения положены следующие принципы:
1) Обрабатывается не все логическое (для упрощения в дальнейшем булево) выражение, а его скелетная схема (СС), содержащая только символы: "(", ")", "[", "]", "&", "|", . При этом круглые скобки рассматриваются как обычные, а квадратные ограничивают инверсию заключенного в них выражения (то есть знак инверсии явно не используется).
Паре скобок (круглых или квадратных) соответствует буква исходного булева выражения, порядковый номер которой есть позиционный порядковый номер указанной пары скобок. Например, булеву выражению вида ((a ~xb)~(cd ~ef) g) соответствует скелетная схема, изображенная на рисунке.
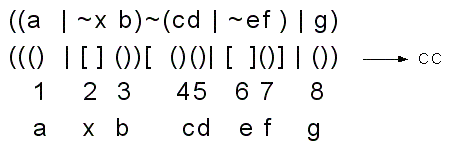
2) Трансляция выполняется поэтапным преобразованием скелетной схемы путем многократных линейных прямых и обратных просмотров (шагов). При каждом просмотре скелетной схемы читается каждый ее символ, нумеруемый посредством стека, и переносится (с возможным видоизменением) во вспомогательную скелетную схему, которая на следующем шаге читается как основная. Также используются таблицы, описывающие вложенность скобок, тип логической операции в скобках и другую информацию.
3) На предпоследнем этапе скелетная схема оптимизируется по возможному числу стековых операций в формируемом коде. Предусмотрена также оптимизация и по другим, перечисленным выше критериям.
4) На последнем этапе трансляции по скелетной схеме строится последовательность команд, реализующих исходное логическое выражение. При этом только заключительный шаг последнего этапа трансляции привязывается к системе команд процессора.
Рассмотрим (укрупненно) этапы трансляции логического выражения.
Этап А. Преобразование булева выражения в скелетную схему (СС).
Шаг А0: подсчет числа h букв в транслируемом выражении и вычисление максимального размера скелетной схемы. Максимальный размер l скелетной схемы по числу символов оценивается как l = 11h + 1. Такой же размер будут иметь стек транслятора и массив номеров символов. Кроме того, резервируется память под массив идентификаторов переменных.
Шаг А1: синтаксический анализ транслируемого выражения и перезапись его в скелетную схему путем замены каждой буквы на пару нумерованных круглых скобок вида «()».
Шаг А2: нумерация скобок и знаков операций.
Шаг А3: исключение знака инверсии и введение при его наличии квадратных скобок (см. выше) вместо круглых.
Этап В. Заключение конъюнкций в скобки.
Шаг В0: перенумерация символов скелетной схемы.
Шаг В1: добавление закрывающих конъюнкции круглых скобок.
Шаг В2: добавление открывающих конъюнкции скобок.
Шаг В3: удаление избыточных скобок.
Этап С. Спуск инверсий. (Перенос квадратных скобок, означающих инверсию, до уровня букв).
Шаг С0: перенумерация символов скелетной схемы.
Шаг С1: построение вектора числа инверсий.
Элементы вектора соответствуют символам (скобкам) скелетной схемы. При просмотре скелетной схемы слева направо модифицируется счетчик числа инверсий: если очередной символ есть открывающая квадратная скобка, то счетчик увеличивается на единицу, если очередной символ есть закрывающая квадратная скобка, то счетчик уменьшается на единицу. Очередному символу соответствует элемент вектора с текущим значением счетчика числа инверсий.
Шаг С2: спуск инверсий.
Реализуется таблицей решений, левая часть которой включает текущий, предыдущий и последующий символы рассматриваемой слева направо скелетной схемы, а также значение соответствующего текущему символу скелетной схемы элемента вектора числа инверсий; правая часть таблицы решений содержит указание на замену текущего символа скелетной схемы на соответствующую скобку. В результате этого шага квадратные скобки соответствуют только буквам булева выражения, остальные квадратные скобки заменяются круглыми. При этом каждая пара квадратных скобок размещается непосредственно рядом и обозначает нечетное число знаков инверсии над соответствующей буквой в исходном булевом выражении.
Шаг С3: удаление избыточных скобок.
Этап D. Оптимизация скелетной схемы по глубине стека.
Можно показать, что последовательность команд контроллера, реализующая булево выражение, использует стек так, что его глубина определяется взаимным расположением операндов. В частности, наименьшая глубина стека обеспечивается такой перестановкой булевой формулы, которая является строго обратной перестановке, обеспечивающей минимум числа путей в соответствующем линейном бинарном графе.
Шаг D1: синтез вектора R внутренних операций. Размер вектора равен числу пар скобок в скелетной схеме. Элемент вектора помечается знаком операции, соответствующей обрамляющей ее паре скобок. Паре скобок, сопоставленной с буквой, ставится в соответствие прочерк. Пример вектора R изображен на рисунке.
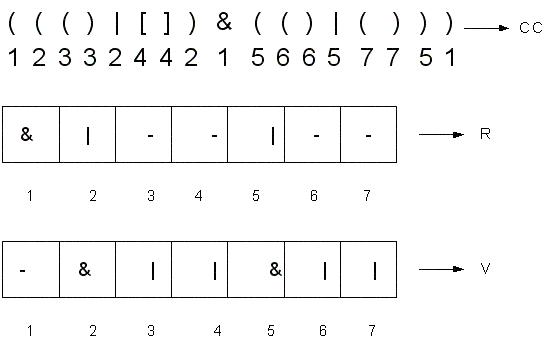
Шаг D2: синтез вектора V внешних операций. Размер вектора равен числу пар скобок в скелетной схеме. Элемент вектора помечается знаком операции, внешней по отношению к данной паре скобок. Пример вектора V представлен на рис. (см. выше)
Шаг D3: перестановка членов скелетной схемы (собственно оптимизация), которая основана на использовании дополнительного стека транслятора. Данная операция является единственной, которая может нарушить линейную зависимость трудоемкости трансляции от числа букв булева выражения. Алгоритм этого шага удобнее всего представить следующей таблицей решений (табл. 1), где С0 – текущий символ скелетной схемы; С1 – следующий символ скелетной схемы; С2 – символ, следующий за С1; знак «->» - переписать в S – стек, или в СС1 – новый вариант скелетной схемы; j+k – перейти к символу скелетной схемы, отстоящему на k позиций правее текущего (j-го).
Таблица 1. Реализация перестановок в скелетной схеме.

В результате применения данного алгоритма в новом варианте скелетной схемы СС1 все пары скобок вида “()” и “[]” оказываются размещенными справа от знаков операций “&” и “|”.
Шаг D4: исключение избыточных знаков операций. После выполнения предыдущего шага могут образоваться лишние знаки операций, размещенные непосредственно после открывающих скобок и которые исключаются на данном шаге.
Напомним, что этап D не является обязательным, если объем оперативной памяти контроллера не служит ограничением.
Этап Е. Синтез промежуточного кода. В промежуточном коде используются значения содержимого аккумулятора А и стека S. Логические операции “&” и “|” обобщенно обозначаются знаком “*”. Этап состоит из единственного шага просмотра символов скелетной схемы слева направо и формирования последовательности действий над аккумулятором и стеком согласно упрощенной таблице решений (табл. 2), в которой t – дополнительный двоичный стек транслятора: 0->t – признак использования только аккумулятора, 1->t – признак использования стека S контроллера, х – буква, соответствующая паре встречно-ориентированных скобок, С-1 – символ скелетной схемы, предшествующий текущему, С-2 – символ скелетной схемы, предшествующий символу С-1, Y – ячейка памяти, соответствующая результату вычисления логического выражения, N - номер скобки.
В результате применения алгоритма на данном этапе генерируется последовательность условных команд над данными типа: буква логического выражения, аккумулятор и стек (промежуточная память).
Таблица 2. Синтез промежуточного кода.

Этап F. Синтез последовательности команд контроллера.
Данный этап является заключительным в трансляции. Исходными данными для него служит последовательность условных команд, полученная на предыдущем этапе, а также синтаксис конкретной системы команд контроллера. Алгоритмы данного этапа не представляют особой ценности, и поэтому не рассматриваются.
Таким образом, в результате трансляции логического выражения формируется фрагмент программы контроллера, оптимизированный по числу обращений к промежуточной памяти.
Оценка длительности представленного метода трансляции булевого выражения является линейно зависимой от числа символов в нем (включая знаки операций и скобки), и определяется по максимальному размеру l скелетной схемы:
Тmax <= l S t = (11h + 1) S t,
где h – число букв булевой формулы, S – число шагов трансляции (посимвольного перебора скелетной схемы), t – наибольшая длительность обработки одного символа скелетной схемы.
|