|
Фёдоров А.Л., Казаров А.С. (dv_kazarov@cge.ru),
Ческис В. Л. (dv_cheskis@cge.ru)
(опубликовано в журнале «Программист» № 11/2002)
С++ является статическим ОО языком: в нем осуществляется статический контроль типов, невозможно динамически менять интерфейс и реализацию классов, отдельных объектов, нет мультиметодов. Статичность даёт преимущество в эффективности и надёжности (многие ошибки выявляются на стадии компиляции), но уменьшает гибкость и ограничивает возможности повторного использования объектов, независимой разработки различных компонент системы. В данной работе предложена реализация эмуляции динамического объектно-ориентированного языка, поддерживающего наследование и мультиметоды. Это позволяет писать эффективные программы на статическом языке, используя динамические вставки (как ассемблерные в С/C++) повышающие гибкость.
В данной идеологии написана библиотека "общих средств Динамической Визуализации многомерных, многопараметровых данных", на основе которой сейчас пишется сразу несколько приложений.
Наша основная цель – создание действительно расширяемых программ.
Расширяемых, а не переписываемых заново!
По-видимому, такая программа должна быть многомодульной , а собственно расширение осуществляться написанием новых модулей. Под модулем здесь и далее мы понимаем «библиотеку», желательно - динамически загружаемую (dll). Разделение кода существенно расширяет возможности его повторного использования. В идеале, большая часть нового приложения получается подбором подходящих модулей и заданием настроек пользователя. Если конвейерный метод производства дал такой эффект в промышленности, почему бы не применить его и в программировании? Один программист (группа, компания) специализируется в написании вычислительных алгоритмов, другой – на визуализации, третий – на диалогах. Кроме всего прочего, разделение труда позволяет «распараллелить» процесс разработки ПО.
Допустим, мы приступаем к созданию программного обеспечения для работы с «геометрическими объектами». При анализе предметной области можно выделить основные «сущности»: точки, отрезки, различные типы линий, плоских фигур и т.п. Объекты класса точка должны предоставлять доступ к её координатам, ломаной линии - количество узлов и доступ к каждому из них. Классы естественно сгруппировать в дерево, в корне которого находится абстрактный геометрический объект, далее идут объект размерности 0, 1, 2, а листами являются окружности, квадраты, точки и пр. . В результате создаётся библиотека (модуль) ГеометрическиеОбъекты, содержащий соответствующие классы.
Когда этот модуль будет написан и отлажен, он может использоваться в различных приложениях, передаваться в другие отделы и фирмы, продаваться как коммерческая библиотека. После этого, внесение в его код изменений становится не безопасным: мы в принципе не можем протестировать всё, что написали наши партнёры и клиенты. Кроме того, модуль может поставляться без исходного кода (только заголовочные файлы и библиотеки) и тогда его модификация становится физически невозможной. К сожалению, мы не можем включить в этот модуль все возможные типы геометрических объектов и предусмотреть все их применения. У этого есть как субъективные: заказчик «сам не знает, чего хочет», он требует одно, а реальным пользователям нужно совсем другое, так и объективные причины. Во-первых, у разных приложений и даже разных пользователей одного приложения требования к модулю совершенно различны. Так, клиент, уже имеющий свой «визуализатор», может не предъявить никаких требований к выводу наших объектов на экран, но уделить большое внимание импорту-экспорту (другим клиентам не нужному). Во-вторых, постоянно меняется сама предметная область. В-третьих, сама программа «подстёгивает воображение» пользователя, новые возможности позволяют ему формулировать новые задачи.
Новые объекты и возможности их использования могут быть реализованы в отдельных модулях (рис. 1.).
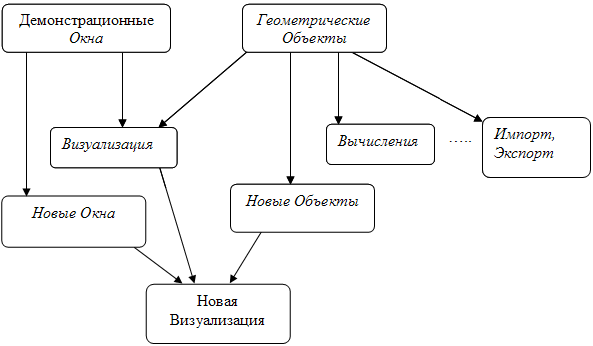
Рис. 1. Упрощённая схема организации многомодульной системы работы с геометрическими объектами
Многомодульная структура системы обладает следующими преимуществами.
-
Расширяемость.
Добавление новых классов и их взаимодействий осуществляется не переписыванием уже имеющегося кода, а разработкой новых модулей.
-
Возможность повторного использования кода.
Модуль ГеометрическиеОбъекты можно включить в любое приложение, если там есть и ДемонстрационныеОкна – можно включить и Визуализацию.
-
Возможность поэтапной реализации программ.
Так, первый релиз может включать ГеометрическиеОбъекты, ДемонстрационныеОкна и Визуализацию, во втором добавятся Вычисления и т.д..
-
Возможность применения конвейерного метода производства, «распараллеливания» процесса разработки ПО.
Включение в систему новых модулей должно удовлетворять нескольким свойствам. Во-первых, при этом не должны переписываться уже существующие. Во-вторых, при объединении нескольких независимо разработанных расширений не должно возникать фатальных последствий для всей системы. Конечно, НовыеОбъекты, вероятнее всего, не начнут рисоваться в НовыхОкнах (для этого надо будет написать или купить ещё один модуль НоваяВизуализация), главное - что бы «старое» продолжало работать. В-третьих, не хотелось бы терять одного из главных преимуществ ООП – наследования. Допустим, вышеперечисленные модули уже написаны и успешно работают. Вы создали новый подкласс линий для каких-то своих, связанных с РассчётомЛиний целей. Все используемые при рисовании методы они поддерживают: предоставляют количество узлов и координаты каждого из них. Почему бы таким линиям не «нарисоваться» автоматически, даже если вы ничего не слышали про ДемонстрационныеОкна и Визуализацию? Аналогично, допустим, вы создали новый класс окон, незначительно отличающийся от родительского. Обидно, если в нём ничего не будет рисоваться!
Статичность С++.
К сожалению, на практике все далеко не так просто: постоянно возникает необходимость «лезть» в уже написанные и отлаженные модули. Основной причиной этого является статичность используемого языка программирования (в нашем случае С++), и, как следствие «навязываемой» им технологии программирования. Под динамичностью языка мы понимаем вовсе не отсутствие общепринятого стандарта и возможность свободного изменения его синтаксиса и семантики! В этом отношении с С++ всё в порядке: с одной стороны, есть утверждённый стандарт, которого худо-бедно придерживаются разработчики компиляторов, с другой – препроцессор и перегружаемые операторы, позволяющие использовать самые причудливые конструкции и менять смысл кода на прямо противоположный. Динамическое программирование из дискретной математики здесь тоже ни при чём. В данной статье динамичность, понимается в смысле близком английскому термину run-time (происходящее во время выполнения программы). Соответственно статическим будем называть то, что осуществляется на этапе компиляции и сборки (линковки) программы.
Есть несколько причин, не позволяющих считать С++ динамическим языком программирования.
-
Статичность интерфейса и реализации класса.
Под интерфейсом класса понимается совокупность его атрибутов и методов (задаётся описанием класса, обычно помещаемым в заголовочный файл), под реализацией – конкретный код, выполняемый при вызове этих методов. Как первое, так и второе должно быть определено ещё до начала компиляции, нельзя run-time добавить в класс переменную или метод, перекрыть уже существующий.
Но при разработке новых модулей постоянно возникает необходимость менять уже существующие классы! Так, при разработке Вычислений, могут понадобиться функции, вычисляющие длину линии, её кривизну в некоторой точке, площадь фигуры. При разработке Визуализации может возникнуть необходимость в таких переменных, как цвет, толщина линии, для плоских фигур часто должна быть построена триангуляция (разбиение на треугольники). Причём вышеперечисленные функции существенно зависят от типа объекта: они должны быть отдельно написаны для прямоугольников, окружностей и произвольных геометрических объектов.
До компиляции и сборки мы не можем изменять «чужие» классы: у нас просто нет их кода. После - тоже не можем. Какая уж тут расширяемость!
-
Статический контроль типов.
При разборе выражения p->f() компилятор «должен быть уверен», что объект, на который ссылается указатель p, действительно содержит метод f(). Даже шаблоны (template) не всегда помогают создать код, обрабатывающий разнотипные объекты: на этапе компиляции и сборки необходимо знать, какие из них требуется инсталлировать, какой применяется в каждом конкретном случае. Попробуйте-ка выполнить задание из листинга 1, не меняя классов и не используя конструкции
if-then-else + dynamic_cast.
/*
Листинг 1. Статический контроль типов ограничивает возможности использования полиморфизма
*/
class baseclass {};
class A:public baseclass
{
public:
A();
// класс A содержит метод void f()
virtual void f();
};
class B:public baseclass
{
public:
B();
// класс B не содержит метод void f()
};
class C:public baseclass {…};
/*
Требуется написать
(не меняя вышеописанных классов и не используя if-then-else + dynamic_cast):
*/
bool CallF(baseclass *p)
{
/*
если определено p->f(), вызвать эту функцию и вернуть true,
иначе – вернуть false
*/
}
C++ предлагает три способа реализовать функцию CallF. Первый (наиболее употребимый) – добавить в baseclass метод bool f(), в тех подклассах, где он имеет смысл – выполнять необходимые действия и возвращать true, в остальных – возвращать false. Второй – создать класс baseclass_f:public baseclass, унаследовать от него все классы, содержащие f(), и использовать dynamic_cast < baseclass_f *> . Третий – пресловутое if-then-else + dynamic_cast в CallF. Первый вариант приводит к засорению базового класса (нельзя же добавлять туда всё подряд!), к тому же baseclass может быть не доступен (например, содержаться в «закрытом» модуле). Второй требует перепроектировать всю систему объектов. А если затем потребуется написать CallG, CallH? Конечно, С++ поддерживает множественное наследование, но иерархия классов при таком подходе сильно усложнится, да и не дело менять её «туда-сюда». Недостатки третьего метода обсуждались неоднократно: функцию CallF придётся переписывать всякий раз, когда появляется новый класс, поддерживающий f().
-
Невозможность run-time менять отдельные объекты классов.
Казалось бы, если объекты принадлежат одному классу, то и вести себя они должны одинаково. Если существующий класс чем-либо не устраивает – «наследуйся» и меняй там что хочешь. Однако возможность динамически менять отдельные объекты класса часто оказывается очень полезной. Конечно, наследование является гибким и удобным способом изменения функциональности классов. Но после того как объект создан, изменить его методы, добавить новые методы и переменные уже нельзя. Для этого необходимо удалить существующий объект, а затем создать новый. При этом надо позаботиться об обновлении всех указателей на данный объект, сохранении его свойств. Кроме того, если каждый раз создавать новые классы, их количество может перейти все разумные границы.
Мультиметоды
Теперь, поговорим о мультиметодах, или «функциях, виртуальных по отношению более чем к одному объекту» (так называется глава в книге С. Мейерса [7]).
Иногда необходимо, чтобы реализация вызова функции выбиралась в зависимости от типов нескольких полиморфных переменных, передаваемых в качестве аргументов.
Пример 1. Пересечение геометрических фигур.
Необходимость в пересечении фигур постоянно возникает как в Визуализации, так и в Вычислениях. Конечно, можно сразу написать её «в общем случае»: каждая фигура разбивается на треугольники, которые затем попарно пересекаются. Однако, гораздо эффективнее будет отдельно обрабатывать пересечение окружности с окружностью, прямоугольником, треугольником, прямоугольника с прямоугольником и т.п.
Сразу приходят в голову перегружаемые (overload) функции, но они нам не помогут. Конечно, в случае, когда компилятору заранее известен точный тип аргументов, он безошибочно подберёт нужную реализацию. А если они являются указателями на базовый класс и выбор зависит от того, каким именно производным классам принадлежат аргументы в каждом конкретном вызове (например, нужно «пройтись» по списку геометрических фигур и найти пересечение каждой с каждой)? Тут сказываются недостатки статического связывания – вызываемая функция должна быть определена ещё на этапе компиляции и сборки. Можно написать пересечение с использованием комбинации if-then-else и dynamic_cast, но тогда её придётся переписывать каждый раз, когда создаётся новый геометрический объект. А если он находится в отдельном модуле?
Пример 2. Визуализация геометрических объектов в демонстрационных окнах.
При параллельной разработке мультиметоды приобретают особую роль: они обеспечивают взаимодействие объектов из разных модулей. Допустим, у нас есть два модуля, скажем ГеометрическиеОбъекты (линии, фигуры, поверхности и т.п.) и ДемонстрационныеОкна (2d, 3d, …).
Естественно, линии, фигуры, поверхности и пр. должны «демонстрироваться» в окнах. Если количество «геометрических объектов» невелико, и все они известны заранее, можно вставить в «окна» соответствующие виртуальные функции (нарисовать окружность, прямоугольник, …), и выбирать необходимую, используя dynamic_cast. Если ограничено число «окон», можно добавить новые методы в «геометрические объекты». При независимой разработке, реализовать это в каком-либо из перечисленных модулей невозможно: там «неизвестны» классы из другого. Но мы можем создать новый модуль – Визуализацию, уже «зависящий» от первых двух, и поместить новые классы (поверхность в 3d окне, карта или пересечение в 2d окне) туда. Теперь, при «бросании» геометрического объекта на окно, будет создаваться новый объект, представляющий его в данном окне. Для этого нам потребуется использовать функцию, виртуальную относительно двух полиморфных переменных: «геометрического объекта» и «демонстрационного окна».
Одной из основных причин отсутствия в С++ функций, виртуальных по отношению к нескольким аргументам является возможность реализовать их уже имеющимися средствами. Например, можно создать таблицу указателей на функцию требуемого типа, и вызывать ту, что находится на пересечении строки, соответствующей точному типу первого аргумента, со столбцом, соответствующим точному типу второго (мы ограничиваемся рассмотрением случая двух параметров, хотя при желании всё можно обобщить на функции произвольной арности). Данный подход позволяет использовать преимущества полиморфизма, но теряется наследование. При добавлении нового производного класса необходимо добавить столбец и/или строку в каждую такую таблицу. Из-за этого, во-первых, быстро растёт объём таблицы, а во-вторых, сильно осложняется модификация системы: для добавления нового метода необходимо «пройтись» по всем существующим подклассам аргументов, при создании производного класса – «добавить его» во все таблицы. Разработка сложных многомодульных проектов в такой ситуации просто невозможна.
И ещё один пример использования мультиметодов. Мы отказались от множественного наследования. Возможно, это было опрометчивое решение: мировая общественность ещё не пришла к единому мнению о его (множественного наследования) целесообразности. Однако наш опыт показывает: использование композиции всегда оказывается более удобным и гибким. Хочешь «скрестить» task и displayed – заведи новый класс с указателями на первый и второй. При этом, во-первых: не придётся заводить сотню «потомков» для всех возможных комбинаций из десятка task и десятка displayed. Во-вторых, при создании нового подкласса task не потребуется изучать всю его «генеалогию» и всех потомков класса displayed. В-третьих, существенно упростится изменение объекта во время выполнения программы – можно переинсталлировать (заменить) как одного «предка», так и обоих сразу. Как поместить такой объект в очередь задач (объектов типа task), список окон (displayed)?
Пример 3. Создание «адаптеров».
Требуется объект класса A вставить в массив указателей на B (применить к нему функцию, аргумент которой объявлен как B* или B&). Можно переунаследовать А от B, но тогда придётся «менять всю систему». Можно создать адаптер – класс, унаследованный от B, но содержащий указатель на А и переадресующий ему запросы. Естественно, функция, создающая адаптер, должна быть виртуальной по отношению к обоим параметрам. Заметим, что её аргументами (во всяком случае, одним из них) являются не объекты, а классы.
Эмуляция таблиц виртуальных функций
Приступим к решению задачи, сформулированной на Листинге 1. Условию удовлетворяет «ответ», приведённый на Листинге 2. (Рассматриваемые на этом и последующих листингах таблицы и функции доступа к ним естественно «инкапсулировать» в отдельные классы. Здесь приводятся лишь «наброски» реализации.)
/*
Листинг 2. Решение задачи из Листинга 1.
*/
class baseclass {};
class A:public baseclass
{
public:
A();
virtual void f();
};
class B:public baseclass
{
public:
B();
};
class C:public baseclass
{
public:
С();
virtual void f();
};
//===============================================================
typedef void(*baseclass_function)( baseclass *obj);
void RegistrateF(const char *key , baseclass_function pf)
{
/*
помещает пару (key, pf) в глобальный ассоциативный массив
(таблицу обработчиков сообщения f)
*/
}
bool CallF(baseclass *p)
{
bool r = false;
/*
если ранее зарегистрирована запись с ключом typeid(*p).name(),
и соответствующий указатель на функцию не равен NULL,
выполнить её, r = true;
*/
return r;
}
…
void call_f_A(baseclass *obj) { ( (A *)obj )->f(); }
void call_f_C(baseclass *obj) { ( (C *)obj )->f(); }
…
RegistrateF(“A” , call_f_A);
RegistrateF(“C” , call_f_C);
Мы создали массив, в котором классу соответствует строка, а значением является адрес функции – обработчика сообщения f. Поскольку доступ к его элементам осуществляется по строке, используется ассоциативный массив, или хэш-таблица. Во время работы программы (обычно при запуске) имеющиеся методы регистрируются, то есть заносятся в таблицу, при обращении к CallF из таблицы выбирается функция, соответствующая классу аргумента, и если эта функция определена, она выполняется. Правда, нам пришлось написать пару «лишних» функций (call_f_A и call_f_C), но их код занял ровно две строчки, а если ещё использовать шаблоны… . Зато CallF реализована не трогая существующие классы.
Если позднее будет добавлен класс D, поддерживающий f, его метод можно зарегистрировать, не меняя функции CallF. Если потом выяснится, что класс B (не имеющий метода f) также должен обрабатывать это сообщение, можно поместить соответствующий код в новую глобальную функцию call_f_B. Зарегистрировав её, мы по сути дела добавим в класс B новый метод, причём сделаем это «не задев» сам класс. Занесённый в таблицу указатель можно динамически удалить, заменить на другой. Один и тот же класс может иметь различные наборы методов в различных конфигурациях системы, пользователь сам сможет формировать его поведение во время работы! Например, в базовой конфигурации, объект «поверхность» может не иметь функции «быстрый просмотр», при добавлении модуля 2D визуализации, она будет изображаться картой, модуля 3D – поверхностью. А при наличии обоих модулей пользователь сможет сам указать, какой вариант ему больше нравится, или вообще отключить эту функцию. Для добавления такой «виртуальной» функции вовсе не обязательно наличия соответствующих методов у классов. Можно просто завести хэш-таблицу и заполнить её указателями на глобальные функции.
Вместо указателей на функции удобнее использовать специально созданные объекты-обработчики данного сообщения. Это позволяет использовать наследование реализации метода, хранить в таком объекте дополнительные параметры, настройки пользователя, разбивать сложные алгоритмы на «простые» шаги и по-разному реализовывать их в подклассах.
Приведённое решение имеет два недостатка, последний из которых - существенный.
Во-первых, недостатком является использование в качестве ключа строки с именем класса. Это замедляет поиск в ассоциативном массиве, увеличивает объём используемой памяти (особенно, если используются длинные имена классов типа mov_data_mapattribute_attractor_index…). Кроме того, в зависимости от компилятора typeid(A).name() может быть “A” или “class A”. Всего этого можно избежать, если вместо строки использовать указатель на type_info.
Во-вторых, мы потеряли одно из главных преимуществ ООП – наследование. Если теперь завести новый класс, скажем class A1:public A {…}, для объекта этого класса функция CallF вернёт false, и ожидаемый пользователем вызов A::f() не произойдёт. Конечно, можно зарегистрировать call_f_A и для класса A1, опять-таки не «потревожив» ни один из этих классов, но …. Независимая разработка модулей в такой ситуации просто невозможна: добавление новых методов и подклассов может происходить параллельно.
А как должна обрабатывать объект класса A1 гипотетическая «правильная» реализация? Сначала, она определит его тип – «A1», проверит наличие для этого класса обработчика сообщения f и не найдёт его. Затем будет определён родительский класс A (несколько таких классов в случае множественного наследования). Для этого класса зарегистрирована функция call_f_A, которая и будет вызвана, CallF вернёт true. Если в информации о типе объекта есть данные о родительском классе, можно пройти всё «генеалогическое древо» объекта и найти требуемый обработчик (или убедиться в его отсутствии). Тогда, создавая классы A2:public A1 , ... , можно не беспокоиться о уже зарегистрированной функции f. Причём call_f_A регистрирует не A::f, а виртуальную функцию f! То есть, если A2 перекрывает эту функцию, ничего «перерегистрировать» не надо (перекрывающий её программист может вообще не знать о нашей таблице)!
К сожалению, стандартная информация о типе type_info не содержит никаких сведений о родительском классе (классах), но это уже – «дело техники». Создадим собственный аналог - class_descriptor, и добавим туда всё, что нам нужно. На первое время хватит строки с именем класса, функции, создающий объект этого класса, и указателя на class_descriptor «родителя» (коллекция таких указателей, если вы используете множественное наследование). Осталось «привязать» class_descriptor’ы к соответствующим классам. Можно создать ещё один ассоциативный массив, ключом в котором будет стандартная информация о типе, а значением – расширенная (указатель на class_descriptor). Но, если всё-таки есть возможность изменить самый базовый baseclass (или написать его с самого начала), лучше просто добавить class_descriptor* прямо туда (см. Листинг 3). Тогда от стандартной RTTI (run-time type information) можно вообще отказаться, в MS Visual C++ отключить соответствующую опцию, что существенно ускорит компиляцию.
/*
Листинг 3. Расширенная информация о типах.
Run-time добавление методов класса с сохранением наследования.
*/
class baseclass;
class class_descriptor
{
public:
char *classname;
class_descriptor *parentclass;
class_descriptor();
virtual baseclass *create();
};
// Функция RegistrateClass заносит аргумент
// в некоторую глобальную таблицу.
// Назначение и реализация последующих соответствует их названиям
void RegistrateClass(class_descriptor *cld);
class_descriptor *FindClass(char * classname);
baseclass *CreateNew (char *classname);
bool IsCastable(class_descriptor *fromclass ,
class_descriptor *toclass );
// следующий макрос может заменить dynamic_cast
#define DV_CAST_CLASS(obj, type) ((obj == NULL)? \
NULL:((obj->IsA(&type##_cld))?(type *)obj:NULL))
class baseclass
{
public:
class_descriptor *cs;
baseclass();
virtual bool IsA(class_descriptor *cld);
// ...
};
class class_descriptor_baseclass:public class_descriptor
{
public:
class_descriptor_baseclass ():class_descriptor()
{
name = “baseclass”;
parentclass = NULL;
}
virtual baseclass *create()
{
return new baseclass;
}
};
extern class_descriptor_baseclass baseclass_cld;
baseclass ::baseclass()
{
cs = &baseclass_cld;
}
//...
RegistrateClass(&baseclass_cld);
//...
extern class_descriptor_A A_cld;
class_descriptor_A:: class_descriptor_A():
class_descriptor_baseclass()
{
name = “A”;
parentclass = &baseclass_cld;
}
//...
RegistrateClass(&A_cld);
//...
//====================================================================
// Таблица обработчиков сообщения f с поддержкой наследования.
//====================================================================
typedef void(*baseclass_function)( baseclass *obj);
// Заносит пару (cld , pf) в ассоциативный массив. cld - ключ
void RegistrateF(class_descriptor *cld , baseclass_function pf);
// Возвращает значение, зарегистрированное с ключом cld ,
// NULL , если такого не оказалось.
baseclass_function GetF(class_descriptor *cld);
bool CallF(baseclass *p)
{
bool r = false;
baseclass_function func = NULL;
for(class_descriptor *cld = p->cs;
cld != NULL; cld = cld->parentclass)
{
func = GetF(cld);
if(func != NULL)
{
func(obj);
r = true;
break;
}
}
return r;
}
//.......
void call_f_A(baseclass *obj) { ( (A *)obj )->f(); }
void call_f_C(baseclass *obj) { ( (C *)obj )->f(); }
...
RegistrateF(&A_cld , call_f_A);
RegistrateF(&C_cld , call_f_C);
Посмотрим, во что нам обошлось «переписывание» RTTI, и что это дало.
Базовые классы и некоторые сервисные функции составляют пару небольших файлов (.cpp и .hpp) и написать их надо один раз. Правда, при создании нового потомка baseclass придётся написать и зарегистрировать соответствующий дескриптор, но это – строк десять кода (при использовании шаблонов – в пять раз меньше). Взамен - получаем возможность самим формировать информацию о типах. В С++ RTTI определена только для полиморфных (имеющих виртуальные функции) классов, а своими средствами можно зарегистрировать и структуры без методов, и встроенные типы (int, double, ...). Информация о родительском классе позволяет не только проверять корректность приведения типа, но и, как показано выше, эмулировать наследование.
Ещё одна дополнительная возможность – создание экземпляра по имени класса (instantiate by name). Это особенно полезно при разборе файлов конфигурации (см. Листинг 4).
/*
Листинг 4. Пример реализации настраиваемого меню.
*/
// Фрагмент текстового файла описания меню.
Menu
{
Item "Параметры " IDM_PARAMETERS menu_processor_dvdata;
Item "Переименовать" IDM_RENAME menu_processor_rename;
Separator;
Item "Удалить" IDM_DELETE menu_processor_dvdata;
}
// .cpp файл
void menu_processor_dvdata::Process(baseclass *obj , char *item)
{
if(strcmp(item, “IDM_PARAMETERS”) == 0)
{
// открыть диалог параметров объекта obj
}
else
if(strcmp(item, “IDM_DELETE”) == 0)
{
// удалить объект
}
// ...
else
{
// обработать ситуацию неизвестного ключевого слова
}
}
// ...
void menu_processor_rename::Process(baseclass *obj , char *item)
// ...
Конфигурация меню описывается в отдельном текстовом файле, который «продвинутый» пользователь может настраивать по своему вкусу: менять текст пунктов (в том числе, переводить на другой язык), их порядок, удалять не нужные и формировать выпадающие подменю.
При выборе пользователем некоторого пункта создаётся (или выбирается уже существующий) объект указанного в соответствующей строке класса, вызывается его метод Process, обрабатывающий данное сообщение.
Если пользователь потребует добавить новую возможность, например, «быстрый просмотр», необходимость менять уже написанный код не возникнет. Можно реализовать эту возможность в новом модуле, там же написать соответствующий menu_processor, и вписать новый пункт в файл конфигурации меню. Если новая возможность «только всё портит», её можно временно отключить, «закоментарив» строку в этом файле (ничего пересобирать не надо!). menu_processor может просто вызывать некоторый виртуальный метод обрабатываемого объекта, тогда его можно использовать в меню различных классов. baseclass не имеет такого метода как «быстрый просмотр»? Не беда, мы уже умеем создавать виртуальные методы во время выполнения программы! Причём реализовывать новый метод мы можем постепенно: сначала для одного класса, затем для другого….
Описанную выше технику можно применить и для реализации мультиметодов (функций, виртуальных относительно нескольких переменных). Ключом в хэш-таблице будет не идентификатор класса объекта, а вектор идентификаторов аргументов. Поиск с учётом наследования можно проводить как по одному параметру, так и по всем.
/*
Листинг 5. Пример реализации мультиметода.
*/
typedef bool (*intersect_function)( Shape *a , Shape *b);
void RegistrateIntersectFunction
(intersect_function func , class_descriptor *f ,
class_descriptor *s);
intersect_function IntersectFunction
(class_descriptor *f , class_descriptor *s);
bool IntersectShapes(Shape *a , Shape *b)
{
bool r = false;
class_descriptor *f = a->cs;
class_descriptor *s = b->cs;
intersect_function func = NULL;
for(; f != NULL && func == NULL; f = f-> parentclass)
for(s = b->cs; s != NULL;s = s-> parentclass)
{
func = IntersectFunction(f , s);
if(func != NULL)
{
r = func(a,b);
break;
}
}
if(func == NULL)
{
/*
Обработать ситуацию «отсутствия обработчика»
*/
}
return r;
}
Мы можем реализовать пересечение геометрических фигур «в общем случае», через триангуляцию, отдать работающую версию пользователям, а затем «потихонечку дописывать» более эффективные алгоритмы для конкретных пар фигур. А можем реализовать самые простые варианты (прямоугольник с прямоугольником), а более сложные – отложить до лучших времён. Если пользователю не нравится наша реализация (и в его распоряжении есть достаточно квалифицированные программисты), он может написать свой вариант и зарегистрировать его в соответствующей таблице. Если у него уже есть свои «наработки», их не придётся переписывать заново: достаточно будет написать подходящие «переходники».
Создание адаптеров, третий из приведённых выше примеров, принципиально отличается от первых двух. При его реализации можно использовать наследование только по одному аргументу – «адаптируемому» классу. Действительно, нам известно только что Adapter(A,B) должен принадлежать классу, производному от B. Если класс B’ унаследован от B, мы не можем «вернуть» результат Adapter(A,B) в качестве Adapter(A,B’) - он может принадлежать некоторому классу B’’, никак с B’ не связанному.
Кстати, собственная RTTI пригодится и в этом случае. В качестве второго параметра может выступать class_descriptor (например, найденный по строке с именем класса), тогда эту функцию можно будет вызывать, не имея экземпляров этого класса. Возвращаемым значением может быть как созданный адаптер, так и class_descriptor.
Динамическое изменение отдельных объектов класса
Таблицу обработчиков сообщения (мультиметодов) можно сделать переменной класса, и тогда для каждого экземпляра может быть выбрана своя стратегия.
Что из себя представляет связывание? Можно предположить, что существует некоторая таблица, в которой содержится информация об идентификаторах (именах) переменных и методов, их типе и «местонахождении» соответствующих данных или кода в памяти. При разборе идентификатора, осуществляется поиск в таблице, если переменная найдена, проверяется соответствие типов (возможно, это делается позднее) и осуществляется собственно связывание обращения к переменной или вызова функции с их размещением в памяти. Приведённая схема сильно упрощена, но в целом она соответствует действительности. Что мешает нам самим завести такую таблицу - реестр, заполнять её во время работы программы и при необходимости получать значения переменных, адреса объектов и функций, изменять их и добавлять новые. Реестр может быть создан для всего приложения (глобальные настройки пользователя и функции системы), так и для каждого окна (и совокупности представляющих его объектов), класса (виртуальные методы, статические переменные) и экземпляра. Более подробно это рассмотрено в статье «Динамическое формирование объектов» [12].
Наибольший эффект достигается совместным использованием нескольких из имеющихся в нашем распоряжении способов задания методов класса: «обычного» (виртуальной функцией), таблицей обработчиков и реестром. Так, глобальная функция-обработчик может вызывать виртуальную функцию (Листинг 2), а «обычный» метод класса может использовать табличные и реестровые.
Историческая справка
Использование таблиц указателей на функции «не что иное, как техника, всегда применявшаяся для имитации виртуальных функций в C» [5]. Эта техника упоминается и подробно рассматривается в [1], [5], [7] , [9-11]. В [9-11] на её основе строится новая парадигма — Процедурно-параметрическое программирование, которая «противопоставляется» ООП. Однако, во всех этих работах не реализовано наследование. Для сохранения наследования предлагается использовать двойной вызов виртуальной функции. В качестве иллюстрации этого приёма приведём пример из [5] (см. Листинг 6.).
В функции IntersectShapes вызов intersect связывается с реализацией intersect(Shape&), определённой в классе, которому принадлежит объект a, скажем Rectangle. Далее, в Rectangle::intersect(Shape&) тип *this известен компилятору, и у объекта b вызывается уже функция intersect(Rectangle&). Рассмотрение такого подхода наверняка доставит ценителю С++ эстетическое удовольствие, но в реальных системах он не применим: попробуйте-ка добавить ещё пару методов и десяток разновидностей Shape! К тому же, что произойдёт, если добавить два новых объекта, скажем Triangle (треугольник) и Ellipse (эллипс), при этом, не написав ни Triangle:: intersect(Ellipse&) ни Ellipse:: intersect(Triangle &) (например, вы купили два независимых расширения к программе)?
Есть подозрение, что вызов IntersectShapes(triangle , ellipse) может зациклиться в
Triangle::intersect(Shape &) - Ellipse:: intersect(Shape &).
Используемые в данной статье class_descriptor’ы есть не что иное, как объекты класса (каждому классу соответствует один объект), описанные в [1]. Кроме информации о родительском классе и имени в них можно хранить информацию о потомках, существующих на данный момент экземплярах, «обычных» переменных и методах данного класса. К производящей функции (create) можно добавить копирование, удаление и т.д.. По смыслу объекты класса близки метаклассам в динамических ОО языках, таких как SmallTalk, Python (см. [8]).
Разнообразные паттерны (приёмы объектно-ориентированного проектирования), в том числе явно и неявно применяемые выше (стратегия, адаптер, фабричный метод и др.) можно найти в [1], [2].
Некая теория создания «расширяемых программ» содержится в [3]. Предложенная в данной статье техника позволяет применять эту теорию на практике, используя все преимущества ООП. Так, ячейки рассматриваемых выше таблиц можно интерпретировать как гнёзда, которые при конфигурировании программы заполняются конкретными модулями, функциями, объектами и данными. Причём мы можем не только заполнять заранее приготовленные гнёзда, но и динамически создавать новые.
О методологиях организации процесса разработки ПО в «экстремальных условиях» говорится в [15].
/*
Листинг 6. Реализация мультиметода двойным вызовом виртуальной функции (из [5]).
*/
class Shape;
class Rectangle;
class Circle;
class Shape{
public:
virtual bool intersect(Shape& otherObject) = 0;
virtual bool intersect (Rectangle& otherObject) = 0;
virtual bool intersect (Circle& otherObject) = 0;
...
};
class Rectangle: public Shape {
public:
virtual bool intersect(Shape& otherObject);
virtual bool intersect (Rectangle& otherObject);
virtual bool intersect (Circle& otherObject);
...
};
class Circle: public Shape {
public:
virtual bool intersect(Shape& otherObject);
virtual bool intersect (Rectangle& otherObject);
virtual bool intersect (Circle& otherObject);
...
};
...
bool Rectangle::intersect(Shape& otherObject)
{
return otherObject.intersect(*this);
}
bool Rectangle::intersect(Rectangle & otherObject)
{
// проверка пересечения Rectangle - Rectangle
}
bool Rectangle::intersect(Circle & otherObject)
{
// проверка пересечения Rectangle - Circle
}
//...
bool IntersectShapes(Shape& a , Shape & b)
{
return a.intersect(b);
}
Практическое применение
Описанные в данной статье идеи на протяжении нескольких лет проверялись и «оттачивались» при реализации геофизического пакета DV-SeisGeo ([13]), расширении его возможностей.
На основе предложенной «идеологии» написана многомодульная библиотека «Общих Средств Динамической Визуализации (DV)», на базе которой сейчас пишутся сразу несколько приложений.
Данная библиотека включает в себя:
-
систему бескоодинатного описания диалогов
-
интерпретатор ОО языка программирования
-
систему управления базами данных (с возможностью визуального конструирования пользовательских запросов к ним)
-
встроенную Пролог-систему (там, где возможно – эффективную)
-
средства динамической визуализации многомерных многопараметровых данных (см. [14])
Разрабатываемые на её основе приложения, включающие динамическую трёхмерную графику и достаточно ресурсоёмкие численные методы, вполне успешно функционирует «в реальном времени». Одно из них содержит: около сорока модулей, более тысячи классов, десятки «табличных» методов и мультиметодов.
Литература
Элджер Дж. С++.– СПб: Питер, 1999 – 320 с.
Гамма Э., Хелм Р., Джонсон Р., Влиссилес Дж. Приёмы объектно-ориентированного проектирования. Паттерны проектирования. - СПб: Питер, 2001 – 368 с.
М. М. Горбунов-Посадов. Расширяемые программы. - Москва: Полиптих, 1999.
Страуструп Б. Язык программирования С++. – СПб.; М.: «Невский диалект» - «Издательство БИНОМ», 1999 г. – 991 с.
Страуструп Б. Дизайн и эволюция C++: Пер. с англ. - М.: ДМК Пресс, 2000. - 448 с.
Л. Аммерааль. STL для программистов на С++. – М.: ДМК, 1999 – 240 с.
Скотт Мейерс.Наиболее эффективное использование С++. 35 новых рекомендаций по улучшению ваших программ и проектов. – М.: ДМК Пресс, 2000 – 304 с.
Р.В. Себеста. Основные концепции языков программирования. – М.: Вильямс, 2001, 672 стр.
Легалов А.И. Процедурно-параметрическое программирование - http://www.softcraft.ru/paradigm/ppp/ , 2001 г.
Легалов А.И. ООП, мультиметоды и пирамидальная эволюция.
"Открытые системы", №3, 2002 г. – http://www.softcraft.ru/coding/evo/
Легалов А.И. Эволюция мультиметодов при процедурном подходе. "Открытые системы", №5, 2002 г. http://www.softcraft.ru/coding/evp/, 2002 г.
Ческис В. Динамическое формирование объектов. // «Программист» № 10/2002. http://www.softcraft.ru/coding/dfo/
Страница пакета DV-SeisGeo: http://www.cge.ru/main/DV/seisgeo/index.html
Кашик А. С. Изучение многомерных многопараметровых пространств на ЭВМ. Их формирование и представление методами динамической визуализации (философия и идеология). «Геофизика», №1, 1998.
Зарин Д., Беликов С. eXtreme Programming – программирование для смелых. // «Программист» № 6,7/2002.
|