[
содержание
| следующая тема
]
Содержание темы
Цели и задачи дисциплины. Основные понятия и определения. Общие особенности языков программирования и трансляторов. Обобщенная структура транслятора. Варианты взаимодействия блоков транслятора.
Цели и задачи дисциплины
В настоящее время искусственные языки, использующие для описания предметной области текстовое представление, широко применяются не только в программировании, но и в других областях. С их помощью описывается структура всевозможных документов, трехмерных виртуальных миров, графических интерфейсов пользователя и многих других объектов, используемых в моделях и в реальном мире. Для того, чтобы эти текстовые описания были корректно составлены, а затем правильно распознаны и интерпретированы, используются специальные методы их анализа и преобразования. В основе методов лежит теория языков и формальных грамматик, а также теория автоматов. Программные системы, предназначенные для анализа и интерпретации текстов, называются трансляторами.
Несмотря на то, что к настоящему времени разработаны тысячи различных языков и их трансляторов, процесс создания новых приложений в этой области не прекращается. Это связно как с развитием технологии производства вычислительных систем, так и с необходимостью решения все более сложных прикладных задач. Кроме того, элементы теории языков и формальных грамматик применимы и в других разнообразных областях, например, при описании структур данных, файлов, изображений, представленных не в текстовом, а двоичном формате. Эти методы полезны и при разработке своих трансляторов даже там, где уже имеются соответствующие аналоги. Такая разработка может быть обусловлена различными причинами, в частности, функциональными ограничениями, отсутствием локализации, низкой эффективностью. Например, одной из последних разработок компании Microsoft является язык программирования C#, а одной из причин его создания является стремление к снижению популярности языка программирования Java. Можно привести множество других примеров, когда разработка своего транслятора может оказаться актуальной. Поэтому, основы теории языков и формальных грамматик, а также практические методы разработки трансляторов лежат в фундаменте инженерного образования по информатике и вычислительной технике.
Предлагаемый материал затрагивает основы методов разработки трансляторов и содержит сведения, необходимые для изучения логики их функционирования, используемого математического аппарата (теории формальных языков и формальных грамматик, метаязыков). Он используется в рамках семестровых лекционных курсов, читаемых для различных специальностей, на факультете информатики и вычислительной техники Красноярского государственного технического университета. В ходе лабораторных работ осуществляется непосредственное знакомство с отдельными методами создания трансляторов.
Цель дисциплины: предоставить знания по основам теории языков и формальных грамматик, теории автоматов, методам разработки трансляторов.
Для достижения поставленной цели в ходе преподавания дисциплины решаются следующие задачи:
- В ходе лекционного курса рассматриваются общие принципы организации процесса трансляции и структуры трансляторов. Изучаются основы теории построения трансляторов.
- На лабораторных занятиях и в ходе самостоятельной работы осуществляется практическое закрепление полученных теоретических знаний: разрабатывается транслятор для простого языка программирования.
Основные понятия и определения
Большинство рассматриваемых определений заимствовано из
[АРНФТСАнгло-русско-немецко-французский толковый словарь по вычислительной технике и обработке данных, 4132 термина. Под. ред. А.А. Дородницына. М.: 1978. 416 с.)].
Транслятор - обслуживающая программа, преобразующая исходную программу, предоставленную на входном языке программирования, в рабочую программу, представленную на объектном языке.
Приведенное определение относится ко всем разновидностям транслирующих программ. Однако у каждой из таких программ могут иметься свои особенности по организации процесса трансляции. В настоящее время трансляторы разделяются на три основные группы: ассемблеры, компиляторы и интерпретаторы.
Ассемблер - системная обслуживающая программа, которая преобразует символические конструкции в команды машинного языка. Специфической чертой ассемблеров является то, что они осуществляют дословную трансляцию одной символической команды в одну машинную. Таким образом, язык ассемблера (еще называется автокодом) предназначен для облегчения восприятия системы команд компьютера и ускорения программирования в этой системе команд. Программисту гораздо легче запомнить мнемоническое обозначение машинных команд, чем их двоичный код. Поэтому, основной выигрыш достигается не за счет увеличения мощности отдельных команд, а за счет повышения эффективности их восприятия.
Вместе с тем, язык ассемблера, кроме аналогов машинных команд, содержит множество дополнительных директив, облегчающих, в частности, управление ресурсами компьютера, написание повторяющихся фрагментов, построение многомодульных программ. Поэтому выразительность языка намного богаче, чем просто языка символического кодирования, что значительно повышает эффективность программирования.
Компилятор - это обслуживающая программа, выполняющая трансляцию на машинный язык программы, записанной на исходном языке программирования. Также как и ассемблер, компилятор обеспечивает преобразование программы с одного языка на другой (чаще всего, в язык конкретного компьютера). Вместе с тем, команды исходного языка значительно отличаются по организации и мощности от команд машинного языка. Существуют языки, в которых одна команда исходного языка транслируется в 7-10 машинных команд. Однако есть и такие языки, в которых каждой команде может соответствовать 100 и более машинных команд (например, Пролог). Кроме того, в исходных языках достаточно часто используется строгая типизация данных, осуществляемая через их предварительное описание. Программирование может опираться не на кодирование алгоритма, а на тщательное обдумывание структур данных или классов. Процесс трансляции с таких языков обычно называется компиляцией, а исходные языки обычно относятся к языкам программирования высокого уровня (или высокоуровневым языкам). Абстрагирование языка программирования от системы команд компьютера привело к независимому созданию самых разнообразных языков, ориентированных на решение конкретных задач. Появились языки для научных расчетов, экономических расчетов, доступа к базам данных и другие.
Интерпретатор - программа или устройство, осуществляющее пооператорную трансляцию и выполнение исходной программы. В отличие от компилятора, интерпретатор не порождает на выходе программу на машинном языке. Распознав команду исходного языка, он тут же выполняет ее. Как в компиляторах, так и в интерпретаторах используются одинаковые методы анализа исходного текста программы. Но интерпретатор позволяет начать обработку данных после написания даже одной команды. Это делает процесс разработки и отладки программ более гибким. Кроме того, отсутствие выходного машинного кода позволяет не "захламлять" внешние устройства дополнительными файлами, а сам интерпретатор можно достаточно легко адаптировать к любым машинным архитектурам, разработав его только один раз на широко распространенном языке программирования. Поэтому, интерпретируемые языки, типа Java Script, VB Script, получили широкое распространение. Недостатком интерпретаторов является низкая скорость выполнения программ. Обычно интерпретируемые программы выполняются в 50-100 раз медленнее программ, написанных в машинных кодах.
Эмулятор - программа или программно-техническое средство, обеспечивающее возможность без перепрограммирования выполнять на данной ЭВМ программу, использующую коды или способы выполнения операция, отличные от данной ЭВМ. Эмулятор похож на интерпретатор тем, что непосредственно исполняет программу, написанную на некотором языке. Однако, чаще всего это машинный язык или промежуточный код. И тот и другой представляют команды в двоичном коде, которые могут сразу исполняться после распознавания кода операций. В отличие от текстовых программ, не требуется распознавать структуру программы, выделять операнды.
Эмуляторы используются достаточно часто в самых различных целях. Например, при разработке новых вычислительных систем, сначала создается эмулятор, выполняющий программы, разрабатываемые для еще несуществующих компьютеров. Это позволяет оценить систему команд и наработать базовое программное обеспечение еще до того, как будет создано соответствующее оборудование.
Очень часто эмулятор используется для выполнения старых программ на новых вычислительных машинах. Обычно новые компьютеры обладают более высоким быстродействием и имеют более качественное периферийное оборудование. Это позволяет эмулировать старые программы более эффективно по сравнению с их выполнением на старых компьютерах. Примером такого подхода является разработка эмуляторов домашнего компьютера ZX Spectrum с микропроцессором Z80. До сих пор находятся любители поиграть на эмуляторе в устаревшие, но все еще не утратившие былой привлекательности, игровые программы. Эмулятор может также использоваться как более дешевый аналог современных компьютерных систем, обеспечивая при этом приемлемую производительность, эквивалентную младшим моделям некоторого семейства архитектур. В качестве примера можно привести эмуляторы IBM PC совместимых компьютеров, реализованные на более мощных компьютерах фирмы Apple. Ряд эмуляторов, написанных для IBM PC, с успехом заменяют различные игровые приставки.
Эмулятор промежуточного представления, как и интерпретатор, могут легко переноситься с одной компьютерной архитектуры на другую, что позволяет создавать мобильное программное обеспечение. Именно это свойство предопределило успех языка программирования Java, с которого программа транслируется в промежуточный код. Исполняющая этот код виртуальная Java машина, является ни чем иным как эмулятором, работающим под управлением любой современной операционной системы.
Перекодировщик - программа или программное устройство, переводящие программы, написанные на машинном языке одной ЭВМ в программы на машинном языке другой ЭВМ. Если эмулятор является менее интеллектуальным аналогом интерпретатора, то перекодировщик выступает в том же качестве по отношению к компилятору. Точно также исходный (и обычно двоичный) машинный код или промежуточное представление преобразуются в другой аналогичный код по одной команде и без какого-либо общего анализа структуры исходной программы. Перекодировщики бывают полезны при переносе программ с одних компьютерных архитектур на другие. Они могут также использоваться для восстановления текста программы на языке высокого уровня по имеющемуся двоичному коду.
Макропроцессор - программа, обеспечивающая замену одной последовательности символов другой
[Браун].
Это разновидность компилятора. Он осуществляет генерацию выходного текста путем обработки специальных вставок, располагаемых в исходном тексте. Эти вставки оформляются специальным образом и принадлежат конструкциям языка, называемого макроязыком. Макропроцессоры часто используются как надстройки над языками программирования, увеличивая функциональные возможности систем программирования. Практически любой ассемблер содержит макропроцессор, что повышает эффективность разработки машинных программ. Такие системы программирования обычно называются макроассемблерами.
Макропроцессоры используются и с языками высокого уровня. Они увеличивают функциональные возможности таких языков как PL/1, C, C++. Особенно широко макропроцессоры применяются в C и C++, позволяя упростить написание программ. Примером широкого использования макропроцессоров является библиотека классов Microsoft Foundation Classes (MFC). Через макровставки в ней реализованы карты сообщений и другие программные объекты. При этом, макропроцессоры повышают эффективность программирования без изменения синтаксиса и семантики языка.
Синтаксис - совокупность правил некоторого языка, определяющих формирование его элементов. Иначе говоря, это совокупность правил образования семантически значимых последовательностей символов в данном языке. Синтаксис задается с помощью правил, которые описывают понятия некоторого языка. Примерами понятий являются: переменная, выражение, оператор, процедура. Последовательность понятий и их допустимое использование в правилах определяет синтаксически правильные структуры, образующие программы. Именно иерархия объектов, а не то, как они взаимодействуют между собой, определяются через синтаксис. Например, оператор может встречаться только в процедуре, а выражение в операторе, переменная может состоять из имени и необязательных индексов и т.д. Синтаксис не связан с такими явлениями в программе как "переход на несуществующую метку" или "переменная с данным именем не определена". Этим занимается семантика.
Семантика - правила и условия, определяющие соотношения между элементами языка и их смысловыми значениями, а также интерпретацию содержательного значения синтаксических конструкций языка. Объекты языка программирования не только размещаются в тексте в соответствии с некоторой иерархией, но и дополнительно связаны между собой посредством других понятий, образующих разнообразные ассоциации. Например, переменная, для которой синтаксис определяет допустимое местоположение только в описаниях и некоторых операторах, обладает определенным типом, может использоваться с ограниченным множеством операций, имеет адрес, размер и должна быть описана до того, как будет использоваться в программе.
Синтаксический анализатор - компонента компилятора, осуществляющая проверку исходных операторов на соответствие синтаксическим правилам и семантике данного языка программирования. Несмотря на название, анализатор занимается проверкой и синтаксиса, и семантики. Он состоит из нескольких блоков, каждый из которых решает свои задачи. Более подробно будет рассмотрен при описании структуры транслятора.
Общие особенности языков программирования и трансляторов
Языки программирования достаточно сильно отличаются друг от друга по назначению, структуре, семантической сложности, методам реализации. Это накладывает свои специфические особенности на разработку конкретных трансляторов.
Языки программирования являются инструментами для решения задач в разных предметных областях, что определяет специфику их организации и различия по назначению. В качестве примера можно привести такие языки как Фортран, ориентированный на научные расчеты, C, предназначенный для системного программирования, Пролог, эффективно описывающий задачи логического вывода, Лисп, используемый для рекурсивной обработки списков. Эти примеры можно продолжить. Каждая из предметных областей предъявляет свои требования к организации самого языка. Поэтому можно отметить разнообразие форм представления операторов и выражений, различие в наборе базовых операций, снижение эффективности программирования при решении задач, не связанных с предметной областью. Языковые различия отражаются и в структуре трансляторов. Лисп и Пролог чаще всего выполняются в режиме интерпретации из-за того, что используют динамическое формирование типов данных в ходе вычислений. Для трансляторов с языка Фортран характерна агрессивная оптимизация результирующего машинного кода, которая становится возможной благодаря относительно простой семантике конструкций языка - в частности, благодаря отсутствию механизмов альтернативного именования переменных через указатели или ссылки. Наличие же указателей в языке C предъявляет специфические требования к динамическому распределению памяти.
Структура языка характеризует иерархические отношения между его понятиями, которые описываются синтаксическими правилами. Языки программирования могут сильно отличаться друг от друга по организации отдельных понятий и по отношениям между ними. Язык программирования PL/1 допускает произвольное вложение процедур и функций, тогда как в C все функции должны находиться на внешнем уровне вложенности. Язык C++ допускает описание переменных в любой точке программы перед первым ее использованием, а в Паскале переменные должны быть определены в специальной области описания. Еще дальше в этом вопросе идет PL/1, который допускает описание переменной после ее использования. Или описание можно вообще опустить и руководствоваться правилами, принятыми по умолчанию. В зависимости от принятого решения, транслятор может анализировать программу за один или несколько проходов, что влияет на скорость трансляции.
Семантика языков программирования изменяется в очень широких пределах. Они отличаются не только по особенностям реализации отдельных операций, но и по парадигмам программирования, определяющим принципиальные различия в методах разработки программ. Специфика реализации операций может касаться как структуры обрабатываемых данных, так и правил обработки одних и тех же типов данных. Такие языки, как PL/1 и APL поддерживают выполнение матричных и векторных операций. Большинство же языков работают в основном со скалярами, предоставляя для обработки массивов процедуры и функции, написанные программистами. Но даже при выполнении операции сложения двух целых чисел такие языки, как C и Паскаль могут вести себя по-разному.
Наряду с традиционным процедурным программированием, называемым также императивным, существуют такие парадигмы как функциональное программирование, логическое программирование и объектно-ориентированное программирование. Надеюсь, что в этом ряду займет свое место и предложенная мною процедурно-параметрическая парадигма программирования
[Легалов2000]. Структура понятий и объектов языков сильно зависит от избранной парадигмы, что также влияет на реализацию транслятора.
Даже один и тот же язык может быть реализован нескольким способами. Это связано с тем, что теория формальных грамматик допускает различные методы разбора одних и тех же предложений. В соответствии с этим трансляторы разными способами могут получать один и тот же результат (объектную программу) по первоначальному исходному тексту.
Вместе с тем, все языки программирования обладают рядом общих характеристик и параметров. Эта общность определяет и схожие для всех языков принципы организации трансляторов.
- Языки программирования предназначены для облегчения программирования. Поэтому их операторы и структуры данных более мощные, чем в машинных языках.
- Для повышения наглядности программ вместо числовых кодов используются символические или графические представления конструкций языка, более удобные для их восприятия человеком.
- Для любого языка определяется:
- Множество символов, которые можно использовать для записи правильных программ (алфавит), основные элементы.
- Множество правильных программ (синтаксис).
- "Смысл" каждой правильной программы (семантика).
Независимо от специфики языка любой транслятор можно считать функциональным преобразователем F, обеспечивающим однозначное отображение X в Y, где X - программа на исходном языке, Y - программа на выходном языке. Поэтому сам процесс трансляции формально можно представить достаточно просто и понятно:
Y = F(X)
Формально каждая правильная программа X - это цепочка символов из некоторого алфавита A, преобразуемая в соответствующую ей цепочку Y, составленную из символов алфавита B.
Язык программирования, как и любая сложная система, определяется через иерархию понятий, задающую взаимосвязи между его элементами. Эти понятия связаны между собой в соответствии с синтаксическими правилами. Каждая из программ, построенная по этим правилам, имеет соответствующую иерархическую структуру.
В связи с этим для всех языков и их программ можно дополнительно выделить следующие общие черты: каждый язык должен содержать правила, позволяющие порождать программы, соответствующие этому языку или распознавать соответствие между написанными программами и заданным языком.
Связь структуры программы с языком программирования называется синтаксическим отображением.
В качестве примера рассмотрим зависимость между иерархической структурой и цепочкой символов, определяющей следующее арифметическое выражение:
a + (b + c) * d
В большинстве языков программирования данное выражение определяет иерархию программных объектов, которую можно отобразить в виде дерева (рис. 1.1.):
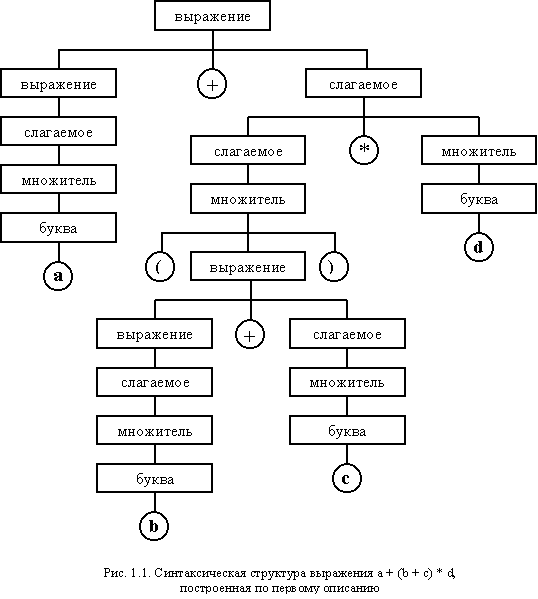
В кружках представлены символы, используемые в качестве элементарных конструкций, а в прямоугольниках задаются составные понятия, имеющие иерархическую и, возможно, рекурсивную структуру. Эта иерархия определяется с помощь синтаксических правил, записанных на специальном языке, который называется метаязыком (подробнее метаязыки будут рассмотрены при изучении формальных грамматик):
<выражение> ::= <слагаемое> | <выражение> + <слагаемое>
<слагаемое> ::= <множитель> | <слагаемое> * <множитель>
<множитель> ::= <буква> | ( <выражение> )
<буква> ::= a | b | c | d | i | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z
Примечание. Знак "::=" читается как "это есть". Вертикальная черта "|" читается как "или".
Если правила будут записаны иначе, то изменится и иерархическая структура. В качестве примера можно привести следующие способ записи правил:
<выражение> ::= <операнд> | <выражение> + < операнд > | <выражение> * < операнд >
<операнд> ::= <буква> | ( <выражение> )
<буква> ::= a | b | c | d | i | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z
В результате синтаксического разбора того же арифметического выражения будет построена иерархическая структура, представленная на рис. 1.2.
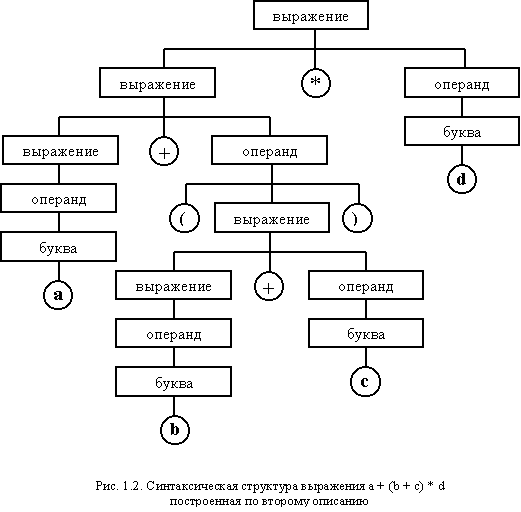
Следует отметить, что иерархическая структура в общем случае может быть никоим образом не связана с семантикой выражения. И в том и другом случае приоритет выполнения операций может быть реализован в соответствии с общепринятыми правилами, когда умножение предшествует сложению (или наоборот, все операции могут иметь одинаковый приоритет при любом наборе правил). Однако первая структура явно поддерживает дальнейшую реализацию общепринятого приоритета, тогда как вторая больше подходит для реализации операций с одинаковым приоритетом и их выполнению справа налево.
Процесс нахождения синтаксической структуры заданной программы называется синтаксическим разбором.
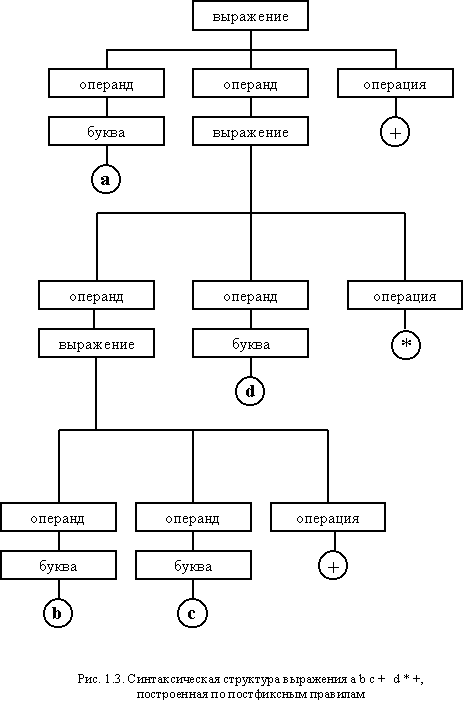
Синтаксическая структура, правильная для одного языка, может быть ошибочной для другого. Например, в языке Форт приведенной выражение не будет распознано. Однако для этого языка корректным будет являться постфиксное выражение:
a b c + d * +
Его синтаксическая структура описывается правилами:
<выражение> ::= <буква> | <операнд> <операнд> <операция>
< операнд > ::= < буква > | < выражение >
< операция > ::= + | *
<буква> ::= a | b | c | d | i | f | g | h | i | j | k | l | m | n | o | p | q | r | s | t | u | v | w | x | y | z
Иерархическое дерево, определяющее синтаксическую структуру, представлено на рис. 1.3.
Другой характерной особенностью всех языков является их семантика. Она определяет смысл операций языка, корректность операндов. Цепочки, имеющие одинаковую синтаксическую структуру в различных языках программирования, могут различаться по семантике (что, например, наблюдается в C++, Pascal, Basic для приведенного выше фрагмента арифметического выражения).
Знание семантики языка позволяет отделить ее от его синтаксиса и использовать для преобразования в другой язык (осуществить генерацию кода).
Описание семантики и распознавание ее корректности обычно является самой трудоемкой и объемной частью транслятора, так как необходимо осуществить перебор и анализ множества вариантов допустимых комбинаций операций и операндов.
Обобщенная структура транслятора
Общие свойства и закономерности присущи как различным языкам программирования, так и трансляторам с этих языков. В них протекают схожие процессы преобразования исходного текста. Не смотря на то, что взаимодействие этих процессов может быть организовано различным путем, можно выделить функции, выполнение которых приводит к одинаковым результатам. Назовем такие функции фазами процесса трансляции.
Учитывая схожесть компилятора и интерпретатора, рассмотрим фазы, существующие в компиляторе. В нем выделяются:
- Фаза лексического анализа.
- Фаза синтаксического анализа, состоящая из:
- распознавания синтаксической структуры;
- семантического разбора, в процессе которого осуществляется работа с таблицами, порождение промежуточного семантического представления или объектной модели языка.
- Фаза генерации кода, осуществляющая:
- семантический анализ компонент промежуточного представления или объектной модели языка;
- перевод промежуточного представления или объектной модели в объектный код.
Наряду с основными фазами процесса трансляции возможны также дополнительные фазы:
2а. Фаза исследования и оптимизации промежуточного представления, состоящая из:
2а.1. анализа корректности промежуточного представления;
2а.2. оптимизации промежуточного представления.
3а. Фаза оптимизации объектного кода.
Интерпретатор отличается тем, что фаза генерации кода обычно заменяется фазой эмуляции элементов промежуточного представления или объектной модели языка. Кроме того, в интерпретаторе обычно не проводится оптимизация промежуточного представления, а сразу же осуществляется его эмуляция.
Кроме этого можно выделить единый для всех фаз процесс анализа и исправление ошибок, существующих в обрабатываемом исходном тексте программы.
Обобщенная структура компилятора, учитывающая существующие в нем фазы, представлена на рис. 1.4.
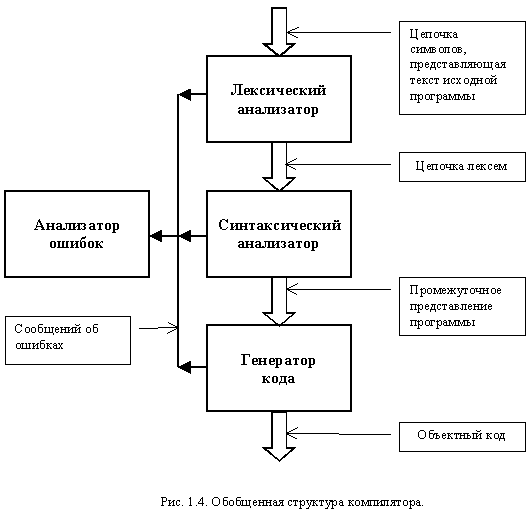
Он состоит из лексического анализатора, синтаксического анализатора, генератора кода, анализатора ошибок. В интерпретаторе вместо генератора кода используется эмулятор (рис. 1.5), в который, кроме элементов промежуточного представления, передаются исходные данные. На выход эмулятора выдается результат вычислений.
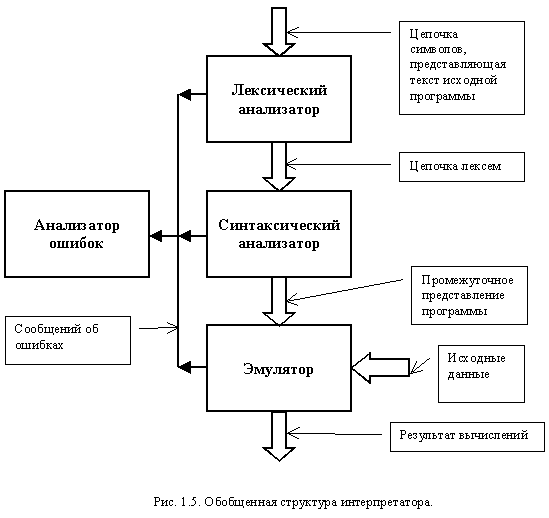
Лексический анализатор (известен также как сканер) осуществляет чтение входной цепочки символов и их группировку в элементарные конструкции, называемые лексемами. Каждая лексема имеет класс и значение. Обычно претендентами на роль лексем выступают элементарные конструкции языка, например, идентификатор, действительное число, комментарий. Полученные лексемы передаются синтаксическому анализатору. Сканер не является обязательной частью транслятора. Однако, он позволяет повысить эффективность процесса трансляции. Подробнее лексический анализ рассмотрен в теме: "Организация лексического анализа".
Синтаксический анализатор осуществляет разбор исходной программы, используя поступающие лексемы, построение синтаксической структуры программы и семантический анализ с формированием объектной модели языка. Объектная модель представляет синтаксическую структуру, дополненную семантическими связями между существующими понятиями. Этими связями могут быть:
- ссылки на переменные, типы данных и имена процедур, размещаемые в таблицах имен;
- связи, определяющие последовательность выполнения команд;
- связи, определяющие вложенность элементов объектной модели языка и другие.
Таким образом, синтаксический анализатор является достаточно сложным блоком транслятора. Поэтому его можно разбить на следующие составляющие:
- распознаватель;
- блок семантического анализа;
- объектную модель, или промежуточное представление, состоящие из таблицы имен и синтаксической структуры.
Обобщенная структура синтаксического анализатора приведена на рис. 1.6.
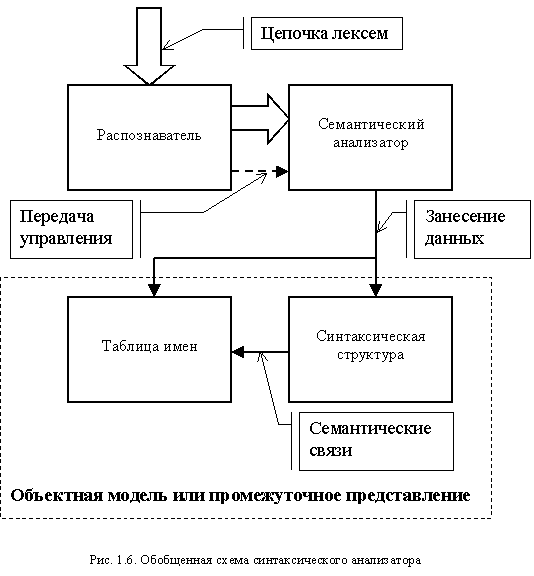
Распознаватель получает цепочку лексем и на ее основе осуществляет разбор в соответствии с используемыми правилами. Лексемы, при успешном разборе правил, передаются семантическому анализатору, который строит таблицу имен и фиксирует фрагменты синтаксической структуры. Кроме этого, между таблицей имен и синтаксической структурой фиксируются дополнительные семантические связи. В результате формируется объектная модель программы, освобожденная от привязки к синтаксису языка программирования. Достаточно часто вместо синтаксической структуры, полностью копирующей иерархию объектов языка, создается ее упрощенный аналог, который называется промежуточным представлением.
Анализатор ошибок получает информацию об ошибках, возникающих в различных блоках транслятора. Используя полученную информацию, он формирует сообщения пользователю. Кроме этого, данный блок может попытаться исправить ошибку, чтобы продолжить разбор дальше. На него также возлагаются действия, связанные с корректным завершением программы в случае, когда дальнейшую трансляцию продолжать невозможно.
Генератор кода строит код объектной машины на основе анализа объектной модели или промежуточного представления. Построение кода сопровождается дополнительным семантическим анализом, связанным с необходимостью преобразования обобщенных команд в коды конкретной вычислительной машины. На этапе такого анализа окончательно определяется возможность преобразования, и выбираются эффективные варианты. Сама генерация кода является перекодировкой одних команд в другие.
Варианты взаимодействия блоков транслятора
Организация процессов трансляции, определяющая реализацию основных фаз, может осуществляться различным образом. Это определяется различными вариантами взаимодействия блоков транслятора: лексического анализатора, синтаксического анализатора и генератора кода. Несмотря на одинаковый конечный результат, различные варианты взаимодействия блоков транслятора обеспечивают различные варианты хранения промежуточных данных. Можно выделить два основных варианта взаимодействия блоков транслятора:
- многопроходную организацию, при которой каждая из фаз является независимым процессом, передающим управление следующей фазе только после окончания полной обработки своих данных;
- однопроходную организацию, при которой все фазы представляют единый процесс и передают друг другу данные небольшими фрагментами.
На основе двух основных вариантов можно также создавать их разнообразные сочетания.
Многопроходная организация взаимодействия блоков транслятора
Данный вариант взаимодействия блоков, на примере компилятора, представлен на рис 1.7.
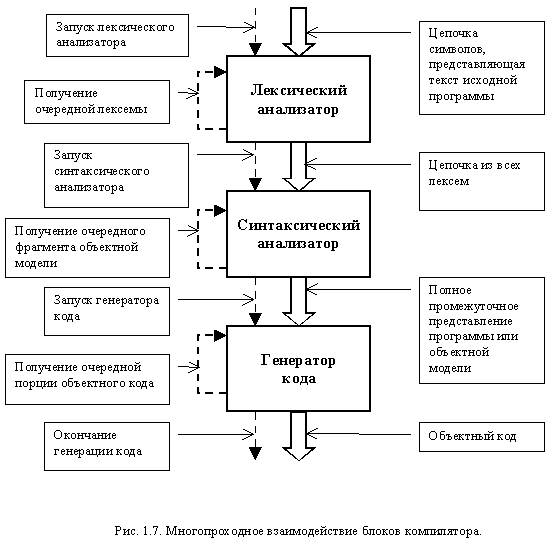
Лексический анализатор полностью обрабатывает исходный текст, формируя на выходе цепочку, состоящую из всех полученных лексем. Только после этого управление передается синтаксическому анализатору. Синтаксический анализатор получает сформированную цепочку лексем и на ее основе формирует промежуточное представление или объектную модель. После получения всей объектной модели он передает управление генератору кода. Генератор кода, на основе объектной модели языка, строит требуемый машинный код
К достоинствам такого подхода можно отнести:
- Обособленность отдельных фаз, что позволяет обеспечить их независимую друг от друга реализацию и использование.
- Возможность хранения данных, получаемых в результате работы каждой из фаз, на внешних запоминающих устройствах и их использования по мере надобности.
- Возможность уменьшения объема оперативной памяти, требуемой для работы транслятора, за счет последовательного вызова фаз.
К недостаткам следует отнести.
- Наличие больших объемов промежуточной информации, из которой в данный момент времени требуется только небольшая часть.
- Замедление скорости трансляции из-за последовательного выполнения фаз и использования для экономии оперативной памяти внешних запоминающих устройств.
Данный подход может оказаться удобным при построении трансляторов с языков программирования, обладающей сложной синтаксической и семантической структурой (например, PL/I). В таких ситуациях трансляцию сложно осуществить за один проход, поэтому результаты предыдущих проходов проще представлять в виде дополнительных промежуточных данных. Следует отметить, что сложные семантическая и синтаксическая структуры языка могут привести к дополнительным проходам, необходимым для установления требуемых зависимостей. Общее количество проходов может оказаться более десяти. На число проходов может также влиять использование в программе конкретных возможностей языка, таких как объявление переменных и процедур после их использования, применение правил объявления по умолчанию и т. д.
Однопроходная организация взаимодействия блоков транслятора
Один из вариантов взаимодействия блоков компилятора при однопроходной организации представлено на рис. 1.8.
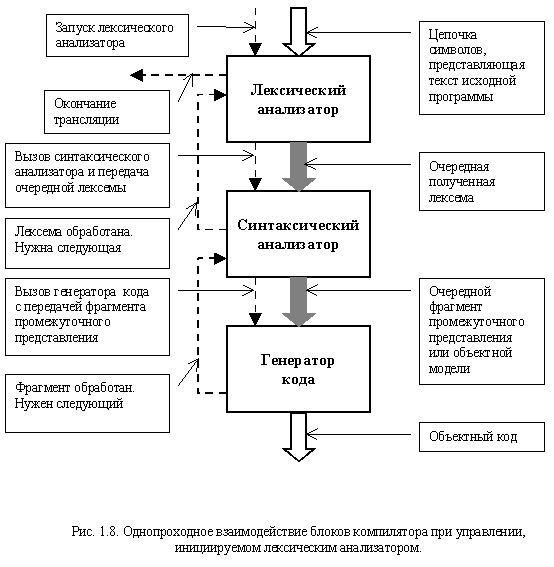
В этом случае процесс трансляции протекает следующим образом. Лексический анализатор читает фрагмент исходного текста, необходимый для получения одной лексемы. После формирования лексемы им осуществляется вызов синтаксического анализатора и передача ему созданной лексемы в качестве параметра. Если синтаксический анализатор может построить очередной элемент промежуточного представления, то он делает это и передает построенный фрагмент генератору кода. В противном случае синтаксический анализатор возвращает управление сканеру, давая, тем самым, понять, что очередная лексема обработана и нужны новые данные.
Генератор кода функционирует аналогичным образом. По полученному фрагменту промежуточного представления он создает соответствующий фрагмент объектного кода. После этого управление возвращается синтаксическому анализатору.
По окончании исходного текста и завершении обработки всех промежуточных данных каждым из блоков лексический анализатор инициирует процесс завершения программы.
Чаще всего в однопроходных трансляторах используется другая схема управления, в которой роль основного блока играет синтаксический анализатор (рис. 1.9).
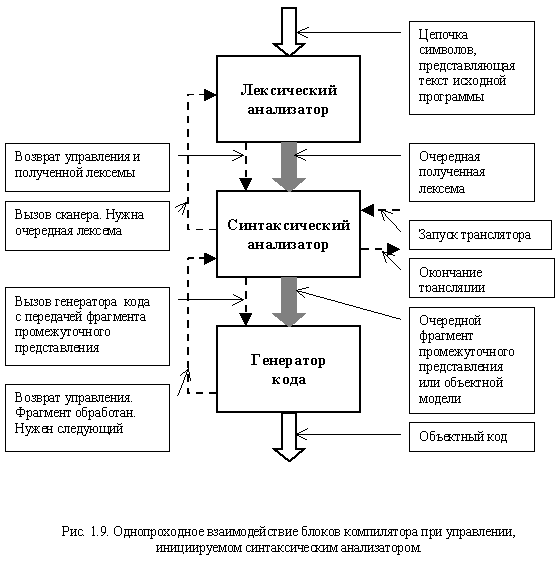
Лексический анализатор и генератор кода выступают в роли вызываемых им подпрограмм. Как только синтаксическому анализатору нужна очередная лексема, он вызывает сканер. При получении фрагмента промежуточного представления осуществляется обращение к генератору кода. Завершение процесса трансляции происходит после получения и обработки последней лексемы и инициируется синтаксическим анализатором.
К достоинствам однопроходной схемы следует отнести отсутствие больших объемов промежуточных данных, высокую скорость обработки из-за совмещении фаз в едином процессе и отсутствие обращений в внешним запоминающим устройствам.
К недостаткам относятся: невозможность реализации такой схемы трансляции для сложных по структуре языков и отсутствие промежуточных данных, которые можно использовать для комплексного анализа и оптимизации.
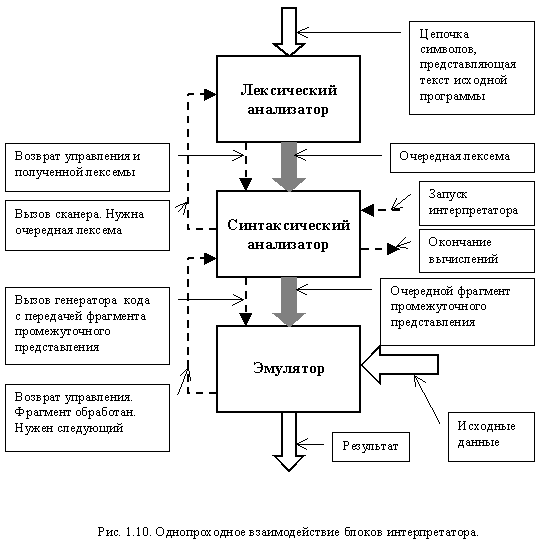
Такая схема часто применяется для простых по семантической и синтаксической структурам языков программирования, как в компиляторах, так и в интерпретаторах. Примерами таких языков могут служить Basic и Pascal. Классический интерпретатор обычно строится по однопроходной схеме, так как непосредственное исполнение осуществляется на уровне отдельных фрагментов промежуточного представления. Организация взаимодействия блоков такого интерпретатора представлена на рис. 1.10.
Комбинированные взаимодействия блоков транслятора
Сочетания многопроходной и однопроходной схем трансляции порождают разнообразные комбинированные варианты, многие из которых успешно используются. В качестве примера можно рассмотреть некоторые из них.
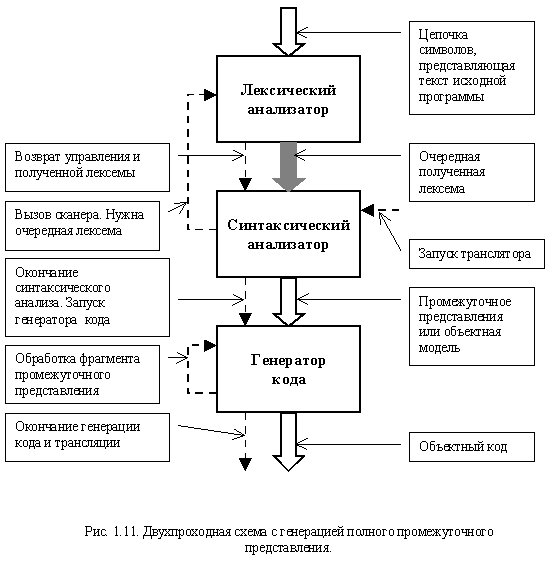
На рис. 1.11 представлена схема взаимодействия блоков транслятора, разбивающая весь процесс на два прохода. На первом проходе порождается полное промежуточное представление программы, а на втором осуществляется генерация кода. Использование такой схемы позволяет легко переносить транслятор с одной вычислительной системы на другую путем переписывания генератора кода.
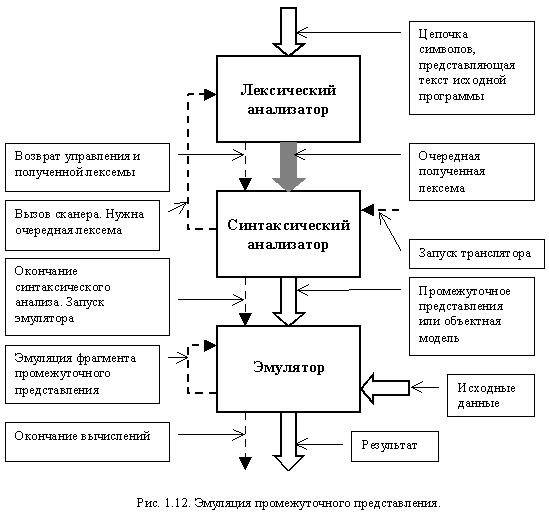
Кроме этого, вместо генератора кода легко подключить эмулятор промежуточного представления, что достаточно просто позволяет разработать систему программирования на некотором языке, ориентированную на различные среды исполнения. Пример подобной организации взаимодействия блоков транслятора представлен на рис. 1.12.
Наряду со схемами, предполагающими замену генератора кода на эмулятор, существуют трансляторы, допускающие их совместное использование. Одна из таких схем представлена на рис. 1.13.
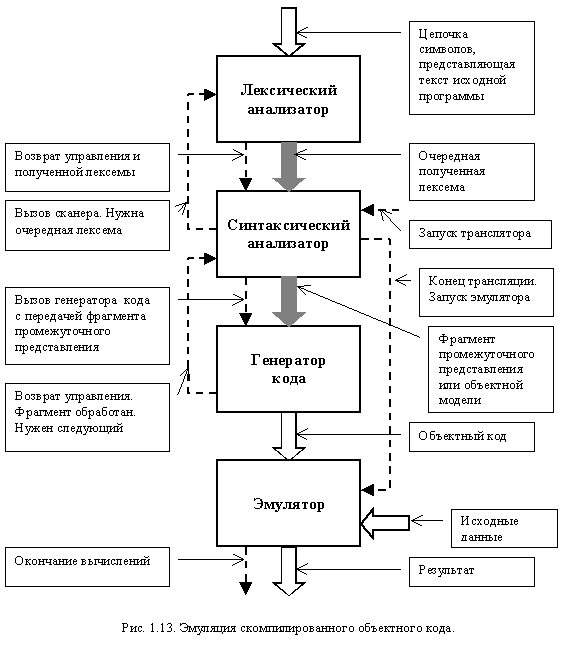 Процесс трансляции, включая и генерацию кода, может быть выполнен за любое число проходов (в примере используется однопроходная трансляция, представленная ранее на рис 1.9). Однако сформированный объектный код не исполняется на соответствующей ему вычислительной системе, а эмулируется на компьютере с другой архитектурой. Такая схема применяется в среде построенной вокруг языка программировании Java. Сам транслятор генерирует код виртуальной Java-машины, эмуляция которого осуществляется специальными средствами как автономно, так и в среде Internet браузера.
Процесс трансляции, включая и генерацию кода, может быть выполнен за любое число проходов (в примере используется однопроходная трансляция, представленная ранее на рис 1.9). Однако сформированный объектный код не исполняется на соответствующей ему вычислительной системе, а эмулируется на компьютере с другой архитектурой. Такая схема применяется в среде построенной вокруг языка программировании Java. Сам транслятор генерирует код виртуальной Java-машины, эмуляция которого осуществляется специальными средствами как автономно, так и в среде Internet браузера.
Представленная схема может иметь и более широкое толкование применительно к любому компилятору, порождающему машинный код. Все дело в том, что большинство современных вычислительных машин реализованы с использованием микропрограммного управления. А микропрограммное устройство управления можно рассматривать как программу, эмулирующую машинный код. Это позволяет говорить о повсеместном использовании последней представленной схемы.
Контрольные вопросы и задания
- Назовите отличия:
- интерпретатора от компилятора;
- компилятора от ассемблера;
- перекодировщика от транслятора;
- эмулятора от интерпретатора;
- синтаксиса от семантики.
- Расскажите об известных Вам последних разработках языков программирования. Приведите основные характеристики названных языков.
- Приведите конкретные примеры использования методов трансляции в областях, не связанных с языками программирования.
- Приведите конкретные примеры компилируемых языков программирования.
- Приведите конкретные примеры интерпретируемых языков программирования.
- Приведите конкретные примеры языков программирования, для которых имеются как компиляторы, так и интерпретаторы.
- Основные достоинства и недостатки компиляторов.
- Основные достоинства и недостатки интерпретаторов.
- Опишите основные различия в синтаксисе двух известных Вам языков программирования.
- Опишите основные различия в семантике двух известных Вам языков программирования.
- Назовите основные фазы процесса трансляции и их назначение.
- Назовите специфические особенности однопроходной трансляции.
- Назовите специфические особенности многопроходной трансляции.
- Приведите примеры возможных комбинаций однопроходной и многопроходной трансляции. Расскажите о практическом использовании этих схем.
[
содержание
| следующая тема
]
|