[
содержание
| предыдущая тема
| следующая тема
]
Содержание темы
Способы определения языков. Формальные грамматики. Грамматики с ограничениями на правила. Способы записи синтаксиса языка. Распознаватели. Контрольные вопросы.
Способы определения языков
Описание языков программирования во многом опирается на теорию формальных языков. Эта теория является фундаментом для организации синтаксического анализа и перевода.
Существует два основных способа определения языков:
- механизм порождения или генератор;
- механизм распознавания или распознаватель.
Они тесно связаны. Первый обычно используется для описания языков, а второй для их реализации. Оба способа позволяют описать языки конечным образом, несмотря на бесконечное число порождаемых ими цепочек.
Неформально язык L - это множество цепочек конечной длины в алфавите T. Механизм порождения позволяет описать языки с помощью системы правил, называемой грамматикой. Цепочки (предложения) языка строятся в соответствии с этими правилами. Достоинство определения языка с помощью грамматик в том, что операции, производимые в ходе синтаксического анализа и перевода, можно делать проще, если воспользоваться структурой, предписываемой цепочкам с помощью этих грамматик.
Механизм распознавания использует алгоритм, который для произвольной входной цепочки остановится и ответит "да" после конечного числа шагов, если эта цепочка принадлежит языку. Если цепочка не принадлежит языку, алгоритм ответит "нет". Распознаватели используются непосредственно при построении синтаксических анализаторов и являются как бы их формальной моделью. Распознаватели строятся на основе теорий конечных автоматов и автоматов с магазинной памятью.
Формальные грамматикиГрамматикой называется четверка G = (N, T, P, S), где N - конечное множество нетерминальных символов (нетерминалов), T - множество терминалов (не пересекающихся с N), S - символ из N, называемый начальным, Р - конечное подмножество множества:
(N ∪ T)* N (N ∪ T)* × (N ∪ T)*,
называемое множеством правил. Множество правил Р описывает процесс порождения цепочек языка. Элемент pi = (α, β) множества Р называется правилом (продукцией) и записывается в виде α. Здесь α и β - цепочки, состоящие из терминалов и нетерминалов. Данная запись может читаться одним из следующих способов:
- цепочка α порождает цепочку β;
- из цепочки α выводится цепочка β.
Таким образом, правило P имеет две части: левую, определяемую, и правую, подставляемую. То есть правило pi - это двойка (pi1, pi2), где pi1 = (N ∪ T)* N (N ∪ T)* - цепочка, содержащая хотя бы один нетерминал, pi2 = (N ∪ T)* - произвольная, возможно пустая цепочка (ε - цепочка).
Если цепочка α содержит pi1, то, в соответствии с правилом pi, можно образовать новую цепочку β, заменив одно вхождение pi1 на pi2. Говорят также, что цепочка β выводится из α в данной грамматике.
Для описания абстрактных языков в определениях и примерах будем пользоваться следующими обозначениями:
- терминалы обозначим буквами a, b, c, d или цифрами 0, 1, ..., 9;
- нетерминалы будем обозначать буквами A, B, C, D, S (причем нетерминал S - начальный символ грамматики);
- буквы U, V, ..., Z используем для обозначения отдельных терминалов или нетерминалов;
- через α, β, γ... обозначим цепочки терминалов и нетерминалов;
- u, v, w, x, y, z - цепочки терминалов;
- для обозначения пустой цепочки (не содержащей ни одного символа) будем использовать знак ε;
- знак “→” будет отделять левую часть правила от правой и читаться как “порождает” или “есть по определению”. Например, A→cd, читается как “A порождает cd”.
Эти обозначения определяют некоторый язык, предназначенный для описания правил построения цепочек, а значит, для описания других языков. Язык, предназначенный для описания другого языка, называется метаязыком.
Пример грамматики G1:
G1 = ({A, S}, {0, 1}, P, S),
где P:
- S → 0A1;
- 0A → 00A1;
- A → ε.
Выводимая цепочка грамматики G, не содержащая нетерминалов, называется терминальной цепочкой, порождаемой грамматикой G.
Язык L(G), порождаемый грамматикой G, - это множество терминальных цепочек, порождаемых грамматикой G.
Введем отношение ⇒G непосредственного вывода на множестве (N ∪ T)*, которое будем записывать следующим образом:
j ⇒Gψ.
Данная запись читается: ψ непосредственно выводима из φ для грамматики G = (N, T, P, S) и означает: если αβγ - цепочка из множества (N ∪ T)* и β → δ - правило из Р то αβγ ⇒G αδγ.
Через ⇒G+ обозначим транзитивное замыкание (нетривиальный вывод за один и более шагов). Тогда j ⇒G+ψ читается как: ψ выводима из φ нетривиальным образом.
Через ⇒G* - обозначим рефлексивное и транзитивное замыкание (вывод за ноль и более шагов). Тогда j ⇒G*ψ означает: ψ выводима из φ.
Пусть ⇒k k - я степень отношения ⇒. То есть, если a ⇒kβ, то существует последовательность α0α1α2α3 ... αk из к+1 цепочек
α = α0, α1, ... αi -1 ⇒ ai, 1 ≤ i ≤ k и αk = β.
Пример выводов для грамматики G1:
S ⇒ 0A1 ⇒ 00A11 ⇒ 0011;
S ⇒1 0A1; S ⇒2 00A11; S ⇒3 0011;
S ⇒+ 0A1; S ⇒+ 00A11; S ⇒+ 0011;
S ⇒* S; S ⇒* 0A1; S ⇒* 00A11; S ⇒* 0011;
где 0011 ∈ L(G1).
Грамматики с ограничениями на правила
Несмотря на большое разнообразие грамматик, при построении трансляторов нашли широкое применение только ряд из них, имеющих некоторые ограничения. Это связано с практической целесообразностью использования определенных типов правил, так как сложность их построения непосредственно влияет на сложность построения трансляторов. По виду правил выделяют несколько классов грамматик. В соответствии с классификацией Хомского грамматика G называется:
- праволинейной, если каждое правило из Р имеет вид: A→xB или A→x, где A, B - нетерминалы, x - цепочка, состоящая из терминалов;
- контекстно-свободной (КС) или бесконтекстной, если каждое правило из Р имеет вид: A→ α, где A ∈ N, а α ∈ (N ∪ T)*, то есть является цепочкой, состоящей из множества терминалов и нетерминалов, возможно пустой;
- контекстно-зависимой или неукорачивающей, если каждое правило из P имеет вид: α → β, где |α| ≤ |β|. То есть, вновь порождаемые цепочки не могут быть короче, чем исходные, а, значит, и пустыми (другие ограничения отсутствуют);
- грамматикой свободного вида, если в ней отсутствуют выше упомянутые ограничения.
Пример праволинейной грамматики:
G2 = ({S}, {0,1}, P, S), где
P:
- S → 0S;
- S → 1S;
- S → ε,
определяет язык {0, 1}*.
Пример КС-грамматики:
G3 = ({E, T, F}, {a, +, *, (,)}, P, E) где
P:
- E →T
- E → E + T
- T → F
- T → T * F
- F → (E)
- F → a.
Данная грамматика порождает простейшие арифметические выражения.
Пример КЗ-грамматики:
G4 = ({B, C, S}, {a, b, c}, P, S) где
P:
1. S → aSBC;
2. S → abc;
3. CB → BC;
4. bB → bb;
5. bC → bc;
6. cC → сc,
порождает язык { a n b n c n }, n ≥ 1.
Примечание 1. Согласно определению каждая праволинейная грамматика является контекстно- свободной.
Примечание 2. По определению КЗ-грамматика не допускает правил: А → ε, где ε - пустая цепочка. Т.е. КС-грамматика с пустыми цепочками в правой части правил не является контекстно-зависимой. Наличие пустых цепочек ведет к грамматике без ограничений.
Соглашение. Если язык L порождается грамматикой типа G, то L называется языком типа G.
Пример: L(G3) - КС язык типа G3.
Наиболее широкое применение при разработке трансляторов нашли КС-грамматики и порождаемые ими КС языки. В процессе изучения КС языков остановимся только на тех, которые будут полезны для нас с практической точки зрения (теория языков обширна и для детального ее изучения необходимо много времени). Те, кто желает приобрести более глубокие познания в данной области, могут обратиться к монографии Ахо и Ульмана
[Ахо78].
Способы записи синтаксиса языка
Существуют различные способы записи синтаксических правил, что в основном определяется условными обозначениям и ограничениями на структуру правил, принятыми в используемых метаязыках. Метаязыки используются для задания грамматики языков программирования со времен Алгола 60. Еще раньше они начали использоваться при описании небольших языков в в статьях, посвященных формальным грамматикам. Кратко рассмотрим основные вехи становления и развития метаязыков. Во всех случаях будем определять идентификатор.
Метаязык Хомского
Метаязык Хомского вышел из недр математической логики. Он имеет следующую систему обозначений:
- символ “→” отделяет левую часть правила от правой (читается как "порождает" и "это есть");
- нетерминалы обозначаются буквой А с индексом, указывающим на его номер;
- терминалы - это символы используемые в описываемом языке;
- каждое правило определяет порождение одной новой цепочки, причем один и тот же нетерминал может встречаться в нескольких правилах слева.
Описание идентификатора на метаязыке Хомского будет выглядеть следующим образом:
|
1. A1 → A |
23. A1 → W |
45. A1 → s |
|
2. A1 → B |
24. A1 → X |
46. A1 → t |
|
3. A1 → C |
25. A1 → Y |
47. A1 → u |
|
4. A1 → D |
26. A1 → Z |
48. A1 → v |
|
5. A1 → E |
27. A1 → a |
49. A1 → w |
|
6. A1 → F |
28. A1 → b |
50. A1 → x |
|
7. A1 → G |
29. A1 → c |
51. A1 → y |
|
8. A1 → H |
30. A1 → d |
52. A1 → z |
|
9. A1 → I |
31. A1 → e |
53. A2 → 0 |
|
10. A1 → J |
32. A1 → f |
54. A2 → 1 |
|
11. A1 → K |
33. A1 → g |
55. A2 → 2 |
|
12. A1 → L |
34. A1 → h |
56. A2 → 3 |
|
13. A1 → M |
35. A1 → i |
57. A2 → 4 |
|
14. A1 → N |
36. A1 → j |
58. A2 → 5 |
|
15. A1 → O |
37. A1 → k |
59. A2 → 6 |
|
16. A1 → P |
38. A1 → l |
60. A2 → 7 |
|
17. A1 → Q |
39. A1 → m |
61. A2 → 8 |
|
18. A1 → R |
40. A1 → n |
62. A2 → 9 |
|
19. A1 → S |
41. A1 → o |
63. A3 → A1 |
|
20. A1 → T |
42. A1 → p |
64. A3 → A3A1 |
|
21. A1 → U |
43. A1 → q |
65. A3 → A3A2 |
|
22. A1 → V |
44. A1 → r |
|
Метаязык Хомского-Щутценберже
Приведенный в предыдущем разделе пример описания идентификатора показывает громоздкость метаязыка Хомского, что позволяет эффективно использовать его только для описания небольших абстрактных языков. Более компактное описание возможно с применением метаязыка Хомского-Щутценберже, использующего следующие обозначения метасимволов:
- символ “=” отделяет левую часть правила от правой (вместо символа “→”);
- нетерминалы обозначаются буквой А с индексом, указывающим на его номер;
- терминалы - это символы используемые в описываемом языке;
- каждое правило определяет порождение нескольких альтернативных цепочек, отделяемых друг от друга символом “+”, что позволяет, при желании, использовать в левой части только разные нетерминалы.
Введение возможности альтернативного перечисления позволило сократить описание языков. Описание идентификатора будет выглядеть следующим образом:
- A1=A+B+C+D+E+F+G+H+I+J+K+L+M+N+O+P+Q+R+S+T+
U+V+W+X+Y+Z+a+b+c+d+e+f+g+h+i+j+k+l+m+n+o+p+q+
r+s+t+u+v+w+x+y+z
- A2=0+1+2+4+5+6+7+8+9
- A3=A1+A3A1+A3A2
Бэкуса-Наура формы (БНФ)
Метаязыки Хомского и Хомского-Щутценберже использовались в математической литературе при описании простых абстрактных языков. Метаязык, предложенный Бэкусом и Науром, впервые использовался для описания синтаксиса реального языка программирования Алгол 60. Наряду с новыми обозначениями метасимволов, в нем использовались содержательные обозначения нетерминалов. Это сделало описание языка нагляднее и позволило в дальнейшем широко использовать данную нотацию для описания реальных языков программирования. Были использованы следующие обозначения:
- символ "::=" отделяет левую часть правила от правой;
- нетерминалы обозначаются произвольной символьной строкой, заключенной в угловые скобки "<" и ">";
- терминалы - это символы, используемые в описываемом языке;
- каждое правило определяет порождение нескольких альтернативных цепочек, отделяемых друг от друга символом вертикальной черты "|".
Пример описания идентификатора с использованием БНФ:
- <буква> :: = А|В|С|D|E|F|G|H|I|J|K|L|M|N|O|P|Q|R|S|T|U|V|
W|X|Y|Z|a|b|c|d|e|f|g|h|i|j|k|l|m|n|o|p|q|r|s|t|u|v|w|x|y|z
- <цифра> :: = 0|1|2|3|4|5|6|7|8|9
- <идентификатор> ::= <буква> | <идентификатор><буква> |
<идентификатор><цифра>
Правила можно задавать и раздельно:
- <идентификатор> :: = <буква>
- <идентификатор> :: = <идентификатор> <буква>
- <идентификатор> :: = <идентификатор> <цифра>
Расширенные Бэкуса-Наура формы (РБНФ)
Метаязыки, представленные выше, позволяют описывать любой синтаксис. Однако, для повышения удобства и компактности описания, целесообразно вести в язык дополнительные конструкции. В частности, специальные метасимволы были разработаны для описания необязательных цепочек, повторяющихся цепочек, обязательных альтернативных цепочек. Существуют различные расширенные формы метаязыков, незначительно отличающиеся друг от друга. Их разнообразие зачастую объясняется желанием разработчиков языков программирования по-своему описать создаваемый язык. К примерам таких широко известных метаязыков можно отнести: метаязык PL/I, метаязык Вирта, используемый при описании Модулы-2, метаязык Кернигана-Ритчи, описывающий Си. Зачастую такие языки называются расширенными формами Бэкуса-Наура (РБНФ).
В частности, РБНФ, используемые Виртом, имеют следующие особенности:
- Квадратные скобки "[" и "]" означают, что заключенная в них синтаксическая конструкция может отсутствовать;
- фигурные скобки "{" и "}" означают ее повторение (возможно, 0 раз);
- круглые скобки "(" и ")" используются для ограничения альтернативных конструкций;
- сочетание фигурных скобок и косой черты "{/" и "/}" используется для обозначения повторения один и более раз. Нетерминальные символы изображаются словами, выражающими их интуитивный смысл и написанными на русском языке.
Если нетерминал состоит из нескольких смысловых слов, то они должны быть написаны слитно. В этом случае для повышения удобства в восприятии фразы целесообразно каждое ее слово начинать с заглавной буквы или разделять слова во фразах символом подчеркивания. Терминальные символы изображаются словами, написанными буквами латинского алфавита (зарезервированные слова) или цепочками знаков, заключенными в кавычки. Синтаксическим правилам предшествует знак "$" в начале строки. Каждое правило оканчивается знаком "." (точка). Левая часть правила отделяется от правой знаком "=" (равно), а альтернативы - вертикальной чертой "|". Этот вариант РБНФ и будет использоваться для описания синтаксиса языков в лабораторной работе. В соответствии с данными правилами синтаксис идентификатора будет выглядеть следующим образом:
$ буква = "A"|"B"|"C"|"D"|"E"|"F"|"G"|"H"|"I"|"J"|"K"|"L"|"M"|"N"|"O"|"P"|"Q"|"R"|
"S"|"T"|"U"|"V"|"W"|"X"|"Y"|"Z"|"a"|"b"|"c"|"d"|"e"|"f"|"g"|"h"|"i"|"j"|"k"|"l"|"m"|"n"|
"o"|"p"|"q"|"r"|"s"|"t"|"u"|"v"|"w"|"x"|"y"|"z".
$ цифра = "0"|"1"|"2"|"3"|"4"|"5"|"6"|"7"|"8"|"9".
$ идентификатор = буква {буква | цифра}.
Диаграммы Вирта
Наряду с текстовыми способами описания синтаксиса языков широко используются и графические метаязыки, среди которых наиболее широкую известность получил язык диаграмм Вирта, впервые примененный для описания языка Паскаль. Метасимволы заменены следующими графическими обозначениями (рис. 2.1):
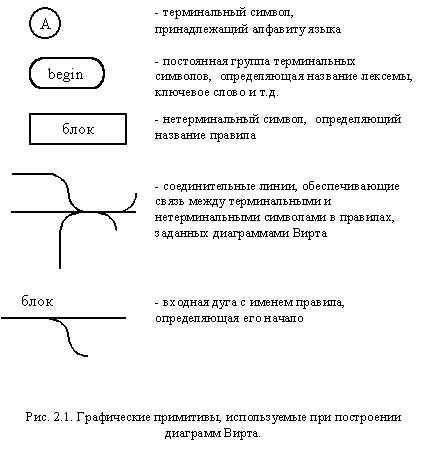
- терминальные символы и их постоянные группы располагаются в окружностях или прямоугольниках со скругленным вертикальными сторонами;
- нетерминальные символы заносятся внутрь прямоугольников;
- каждый графический элемент, соответствующий терминалу или нетерминалу, имеет по одному входу и выходу, которые обычно рисуются на противоположных сторонах;
- каждому правилу соответствует своя графическая диаграмма, на которой терминалы и нетерминалы соединяются посредством дуг;
- альтернативы в правилах задаются ветвлением дуг, а итерации - их слиянием;
- должна быть одна входная дуга (располагается обычно слева и сверху), задающая начало правила и помеченная именем определяемого нетерминала, и одна выходная, задающая его конец (обычно располагается справа и снизу).
Пример описания идентификатора с использованием диаграмм Вирта представлен на рис 2.2.
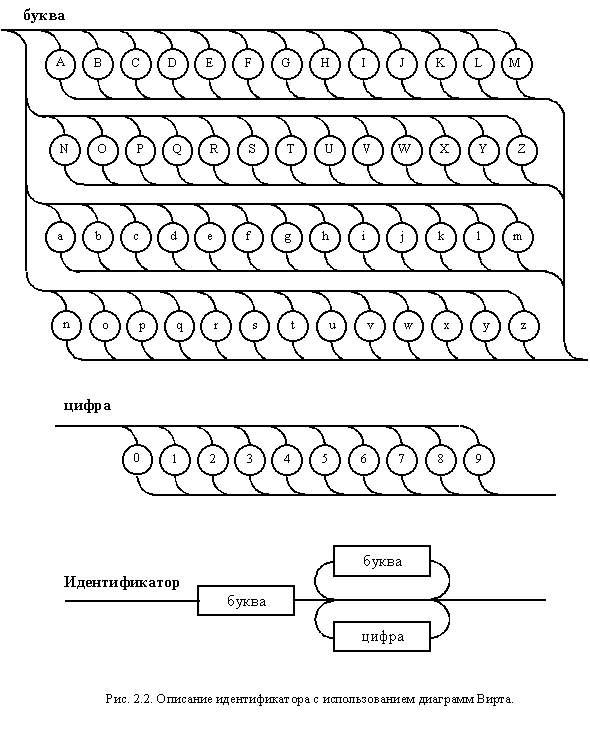
Обычно стрелки на дугах диаграмм не ставятся, а направления связей отслеживаются движением от начальной дуги в соответствии с плавными изгибами промежуточных дуг и ветвлений. Таким же образом определяются входы и выходы терминалов и нетерминалов. Специальных стандартов на диаграммы Вирта нет, поэтому графические обозначения могут меняться в зависимости от средств рисования. Можно, например, использовать псевдографику или просто текстовые символы, связи со стрелками. Однако такой вид правил менее удобен для восприятия и поэтому применяется крайне редко.
Диаграммы Вирта позволяют задавать альтернативы, рекурсии, итерации и по изобразительной мощности эквивалентны РБНФ. Но графическое отображение правил более наглядно. Кроме этого допускается произвольное проведение дуг, что уменьшает количество элементов в правиле за счет его неструктурированности. Диаграммы Вирта являются удобным исходным документом для построения лексического и синтаксического анализаторов.
Распознаватели
Распознаватель – это очень схематизированный алгоритм, определяющий некоторое множество. Его можно представить в виде устройства (автомата). Этот автомат состоит из трех частей: входной ленты, устройства управления с конечной памятью и вспомогательной (рабочей) памяти (рис 2.3).
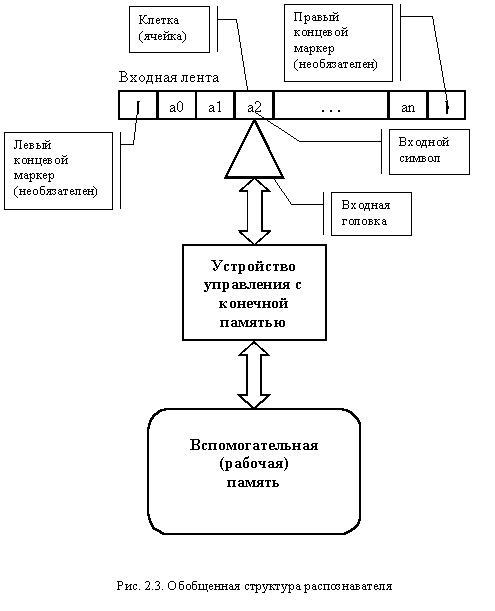
Входная лента – линейная последовательность клеток (ячеек), каждая из которых содержит один входной символ из конечного входного алфавита. Могут присутствовать левый и правый концевые маркеры, может присутствовать только один концевой маркер (левый или правый), могут отсутствовать оба маркера.
Входная головка – в каждый момент читает одну входную ячейку. За один шаг входная головка может сдвинуться на одну ячейку влево, вправо и остаться неподвижной.
Распознаватель, никогда не передвигающий входную головку влево, называется односторонним. Обычно предполагается, что входная головка только читает. Но могут быть такие распознаватели, у которых входная головка и читает, и пишет.
Память – хранит информацию, построенную только из символов конечного алфавита памяти. Может иметь различную структуру: очередь, стек (магазин) и т. д. Можно читать из вспомогательной памяти и писать в нее. Для стека и очереди используются специфические операции (вталкивание, выталкивание).
Устройство управления с конечной памятью – программа, управляющая поведением распознавателя. Может являться аналогом конечного автомата. Определяет перемещение входной головки и работу с памятью на каждом шаге (такте). Переходит за шаг из одного состояния в другое.
Конфигурация распознавателя – мгновенный снимок, на котором изображены:
- состояние устройства управления;
- содержимое входной ленты;
- содержимое памяти.
Начальная конфигурация – устройство управления находится в заданном начальном состоянии, входная головка читает самый левый символ на входной ленте, память имеет заранее установленное начальное содержимое.
Заключительная конфигурация – устройство управления находится в одном из состояний, принадлежащем заранее выделенному множеству заключительных состояний, входная головка обозревает правый концевой маркер или, если маркер отсутствует, сошла с конца входной ленты. Иногда требуется, чтобы заключительная конфигурация памяти удовлетворяла некоторым условиям.
Распознаватель допускает входную цепочку ω, если, начиная с начальной конфигурации, в которой цепочка ω записана на входной ленте, распознаватель может проделать последовательность шагов, заканчивающуюся заключительной конфигурацией.
Язык, определяемый распознавателем – это множество цепочек, которые он допускает.
Для каждой из грамматик, приведенных выше в соответствии с иерархией Хомского, существуют распознаватели определяющие один и тот же класс языков.
- Язык L праволинейный тогда и только тогда, когда он определяется конечным, односторонним детерминированным автоматом.
- Язык L контекстно-свободный тогда и только тогда, когда он определяется односторонним недетерминированным автоматом с магазинной памятью.
- Язык L контекстно-зависимый тогда и только тогда, когда он определяется двухсторонним недетерминированным линейно ограниченным автоматом.
- Язык L рекурсивно перечислимый тогда и только тогда, когда он определяется машиной Тьюринга.
Данные определения показывают, что теория языков и формальных грамматик продвинулась достаточно далеко, чтобы служить самостоятельным предметом изучения. Не будем вдаваться в детали и выяснять смысл представленных понятий. Зафиксируем только сам факт эквивалентности между механизмами порождения и распознавания.
Контрольные вопросы и задания
- Назовите основные способы определения формальных языков и их отличия.
- Дайте определение формальной грамматики.
- Для чего нужны метаязыки?
- Чем является формальный язык, порождаемый грамматикой?
- Определите отношения вывода и назовите отличия, существующие между ними.
- Для грамматики G3 приведите пример вывода терминальной цепочки, содержащей три знака умножения и два знака сложения.
- Приведите пример цепочки для грамматики G3, содержащей пять операндов. Осуществите вывод этой цепочки из начального нетерминала.
- Напишите выражения, удовлетворяющие условиям, приведенным в заданиях 6 и 7, полученные при этом за минимальное число шагов.
- Напишите выражения, удовлетворяющие условиям, приведенным в заданиях 6 и 7, полученные при этом за максимальное число шагов.
- Дайте определение распознавателя. Приведите его структуру.
- Назовите известные Вам классы грамматик с ограничениями на правила. Дайте их определения.
- Чем отличается язык, определяемый формальной грамматикой, от языка, определяемого распознавателем?
- Назовите эквивалентные соотношения между определениями формальных языков с помощью распознавателей и грамматик, заданных иерархией Хомского.
- Опишите с помощью диаграмм Вирта синтаксис языка программирования, заданного
вариантом лабораторной работы. Если возникнут проблемы, то переходите к изучению следующей темы. После чего повторите этот шаг.
[
содержание
| предыдущая тема
| следующая тема
]
|